我的资料框的缩短版本如下所示:
df_crop = pd.DataFrame({
'Name' : ['Crop1', 'Crop1', 'Crop1', 'Crop1', 'Crop2', 'Crop2', 'Crop2', 'Crop2'],
'Type' : ['Area', 'Diesel', 'Fert', 'Pest', 'Area', 'Diesel', 'Fert', 'Pest'],
'GHG': [14.9, 0.0007, 0.145, 0.1611, 2.537, 0.011, 0.1825, 0.115],
'Acid': [0.0125, 0.0005, 0.0029, 0.0044, 0.013, 0.00014, 0.0033, 0.0055],
'Terra Eutro': [0.053, 0.0002, 0.0077, 0.0001, 0.0547, 0.00019, 0.0058, 0.0002]
})
我现在需要使用产量对资料帧中的所有值进行标准化,产量因作物而异,但不是每种型别:
s_yield = pd.Series([0.388, 0.4129],
index=['Crop1', 'Crop2'])
我需要保留“型别”中的信息。如果我尝试使用,.mul()由于索引重复,我会收到一个错误:ValueError: cannot reindex from a duplicate axis.
我唯一的其他想法是使用,.loc()但我有很多列(16 列有要标准化的值),但没有想到任何有效的方法。有什么建议?
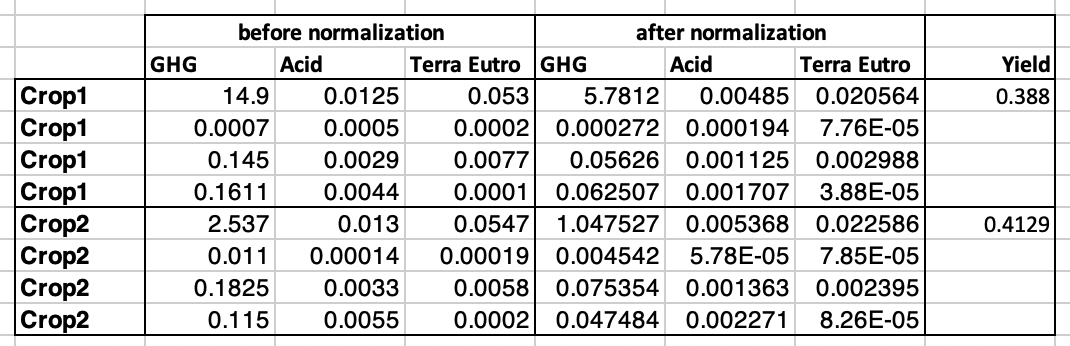
编辑:下表可能有助于显示我尝试实作的目标:
uj5u.com热心网友回复:
获取数字资料并使用系列相乘
numeric_df = df_crop.select_dtypes('number')
df_crop[numeric_df.columns] = numeric_df.mul(df_crop.Name.map(s_yield), axis=0)
输出
Name Type GHG Acid Terra Eutro
0 Crop1 Area 5.781200 0.004850 0.020564
1 Crop1 Diesel 0.000272 0.000194 0.000078
2 Crop1 Fert 0.056260 0.001125 0.002988
3 Crop1 Pest 0.062507 0.001707 0.000039
4 Crop2 Area 1.047527 0.005368 0.022586
5 Crop2 Diesel 0.004542 0.000058 0.000078
6 Crop2 Fert 0.075354 0.001363 0.002395
7 Crop2 Pest 0.047483 0.002271 0.000083
uj5u.com热心网友回复:
为 df_crop 设定索引,并与系列相乘,在相关级别上对齐:
temp = df_crop.set_index(['Name', 'Type'])
temp.mul(s_yield, level='Name', axis = 0).reset_index()
Name Type GHG Acid Terra Eutro
0 Crop1 Area 5.781200 0.004850 0.020564
1 Crop1 Diesel 0.000272 0.000194 0.000078
2 Crop1 Fert 0.056260 0.001125 0.002988
3 Crop1 Pest 0.062507 0.001707 0.000039
4 Crop2 Area 1.047527 0.005368 0.022586
5 Crop2 Diesel 0.004542 0.000058 0.000078
6 Crop2 Fert 0.075354 0.001363 0.002395
7 Crop2 Pest 0.047483 0.002271 0.000083
uj5u.com热心网友回复:
从 pandas 0.24.0 开始,您可以直接将系列合并到资料框,只要系列命名为:
df_merged = df_crop.merge(s_yield.rename('yield'), left_on = 'Name', right_index = True)
然后根据需要乘以列。
uj5u.com热心网友回复:
您可以使用s_yield.map将系列扩展到资料帧的长度,并且可以使用df.select_dtypes来查找特定 dtype(s) 的所有列和多个列:
cols = df_crop.select_dtypes('number').columns
df_crop[cols] = df_crop[cols].mul(df_crop['Name'].map(s_yield), axis=0)
输出:
>>> df_crop
Name Type GHG Acid Terra Eutro
0 Crop1 Area 5.781200 0.004850 0.020564
1 Crop1 Diesel 0.000272 0.000194 0.000078
2 Crop1 Fert 0.056260 0.001125 0.002988
3 Crop1 Pest 0.062507 0.001707 0.000039
4 Crop2 Area 1.047527 0.005368 0.022586
5 Crop2 Diesel 0.004542 0.000058 0.000078
6 Crop2 Fert 0.075354 0.001363 0.002395
7 Crop2 Pest 0.047483 0.002271 0.000083








0 评论