文章目录
- 题目设计
- 解题步骤(Writeup)
题目附件请自取:
链接:https://pan.baidu.com/s/1u8jiXfpD7HvoQTCe4fW80w
提取码:4whw
题目设计
- 考察知识点:
资料处理、wav档案头、高低振幅转换、LSB隐写 - 题目思路:
逆序字节流资料->wav档案->高低振幅转换->LSB隐写->异或测验
以下是设计题目时所用到的脚本
档案转换二进制01资料
from binascii import *
with open('1.png', 'rb') as f:#需要转换的档案
with open('bin.txt', 'w') as f1:
hex_data = hexlify(f.read()).decode()
for i in range(0, len(hex_data), 2):
data = '{:08b}'.format(int(hex_data[i:i+2], 16))
f1.write(data)
二进制资料转换wav高低振幅
import wave,struct,random
sampleRate = 44100.0
obj = wave.open('sound.wav','w')
obj.setnchannels(1)
obj.setsampwidth(2)
obj.setframerate(sampleRate)
with open('bin.txt', 'r') as f:
bin_data = f.read()
for i in bin_data:
if i == '1':
if random.randint(0,1) == 1:
obj.writeframesraw(struct.pack('<h', random.randint(30000, 32000)))
else:
obj.writeframesraw(struct.pack('<h', random.randint(-32000, -30000)))
elif i == '0':
if random.randint(0,1) == 1:
obj.writeframesraw(struct.pack('<h', random.randint(18000, 20000)))
else:
obj.writeframesraw(struct.pack('<h', random.randint(-20000, -18000)))
else:
break
obj.close()
逆序档案字节流
from binascii import *
with open('sound.wav', 'rb') as f:
hex_data = hexlify(f.read()).decode()[::-1]
with open('sound', 'wb') as f1:
for i in range(0, len(hex_data), 2):
data = hex_data[i:i+2][::-1]
f1.write(unhexlify(data))
对档案整体进行异或
from binascii import *
with open('qrcode.png', 'rb') as f:
all_data = f.read()
with open('data', 'wb') as f1:
for i in range(len(all_data)):
f.seek(i)
data = int(hexlify(f.read(1)), 16)
xor_data = '{:02x}'.format(data ^ 0x7f)
f1.write(unhexlify(xor_data))
解题步骤(Writeup)
what档案开头并不是什么型别的档案头

档案尾发现端倪,RIFF、 WAVE、fmt等字样,很明显这是wav档案的档案头

使用Python简单处理、反转字节流资料等到正确的wav档案
from binascii import *
with open('what', 'rb') as f:
hex_data = hexlify(f.read()).decode()[::-1]
with open('data.wav', 'wb') as f1:
for i in range(0, len(hex_data), 2):
data = hex_data[i:i+2][::-1]
f1.write(unhexlify(data))
得到的wav档案使用Audacity分析
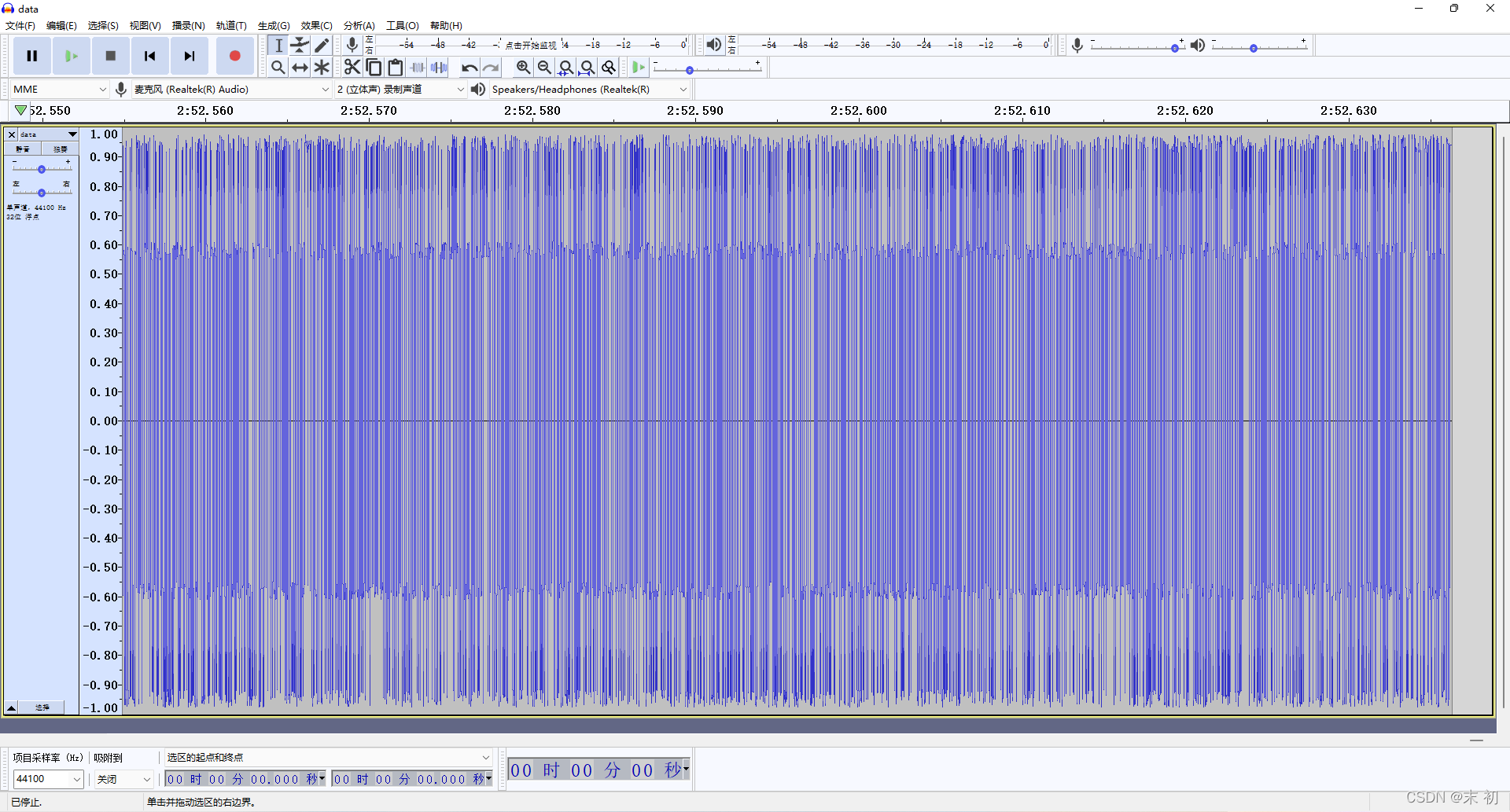
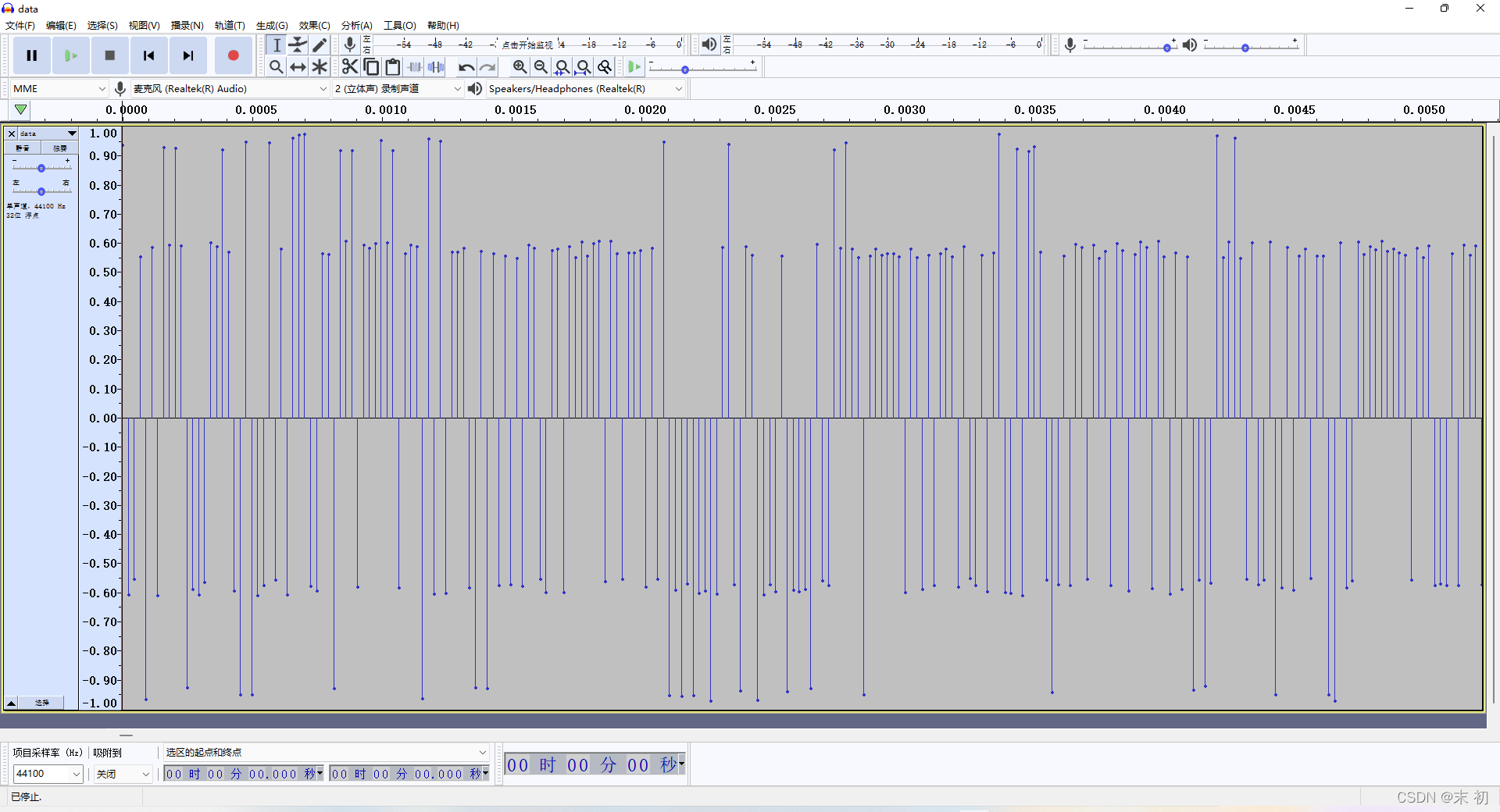
通过分析不难发现,每一帧高低频区别明显,高频在一定的范围内,低频也在一定的范围内
- Python wav模块档案: https://docs.python.org/zh-cn/3/library/wave.html#module-wave
首先来简单分析下振幅的规律
import wave
obj = wave.open('data.wav', 'r')
frames = obj.getnframes()
print("All Frames: {}".format(frames))
frames_data = obj.readframes(20).hex()#提取出前20帧的资料
for i in range(0, len(frames_data), 4):
data = frames_data[i:i+4]
real_data = int(data[2:] + data[:2], 16)
data1 = data[2:] + data[:2]
print("第{:<2}帧: {} => {} 真实资料值: {}".format(int((i+4)/4), data,data1 , real_data))
提取出来的每一帧的资料大小为两字节,且存盘方式为小端存盘,所以需要高位元组位和低位元组位换一下,然后转换成数值
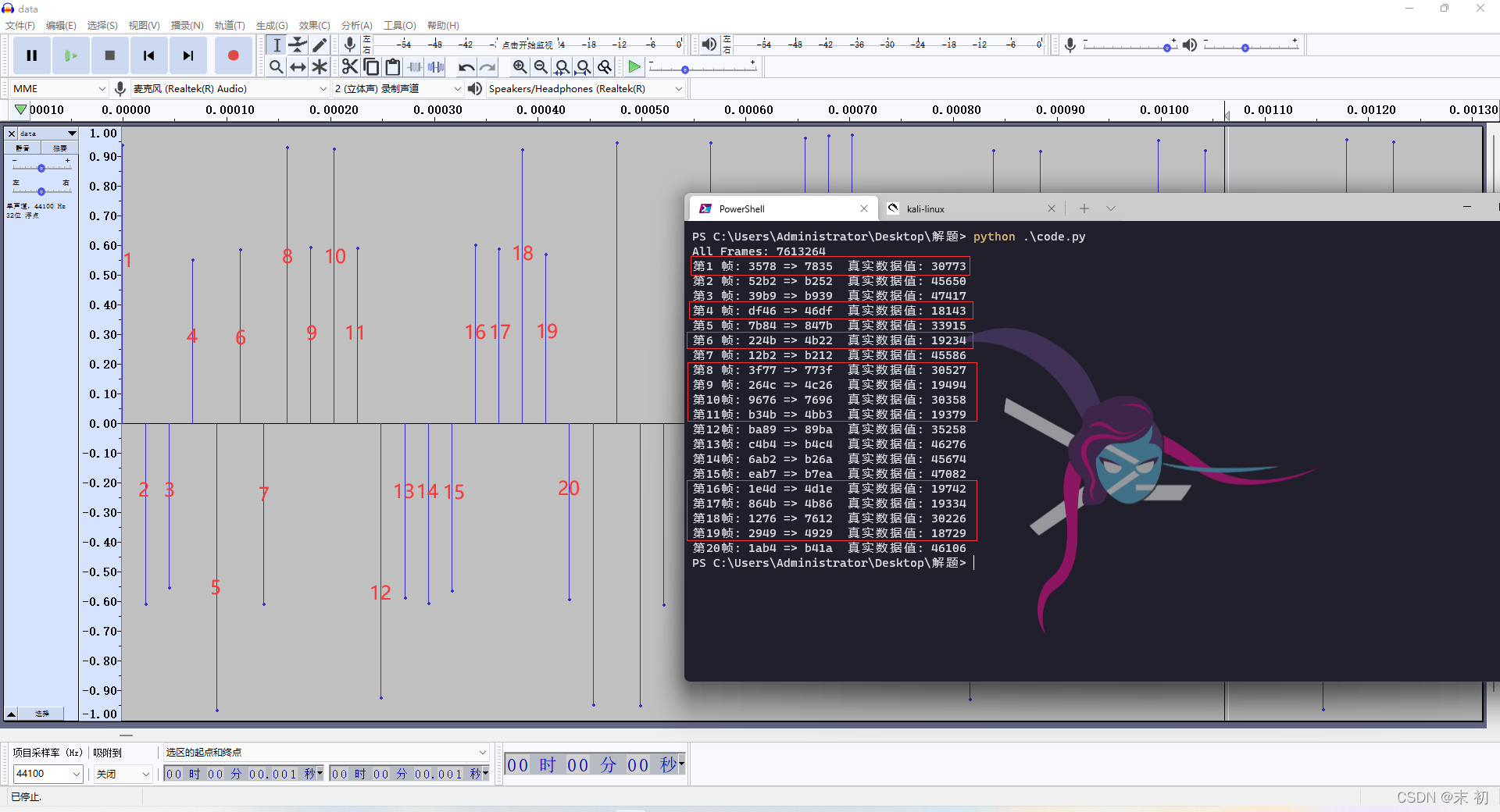
先分析正振幅的资料值,通过多次尝试分析,基本就可以确认高振幅范围为:30000-32000,低振幅范围为:18000-20000
PS:分析高低振幅取值范围可以提升提取出来的帧数来进行更精确的判断
而负振幅资料无论高振幅还是低振幅,为什么都看起来都不在这个范围之内呢,明明从Audacity中观察到的波形的高低范围和正振幅范围都应该是一样的,而得到的数值确大相径庭呢?
我们知道如果是带符号的2字节整型的取值范围是:[-2^(15)] ~ [2^(15)-1]也就是-32768至32767之间
那么就能解释负振幅资料的问题了,很明显发生了溢位;需要对数值进行一个转换处理即可得到在范围内的正常的资料
>>> import math
>>> math.pow(2,15)-(45650-math.pow(2,15))
19886.0#第二帧
>>> math.pow(2,15)-(47417-math.pow(2,15))
18119.0#第三帧
>>> math.pow(2,15)-(33915-math.pow(2,15))
31621.0#第五帧
>>> math.pow(2,15)-(35258-math.pow(2,15))
30278.0#第十二帧
OK,这样就解决了负振幅资料转换的问题
接下来就直接使用Python简单处理,将高低振幅转换成二进制资料即可;然后将得到的二进制资料写成字节流转成档案
import wave, math, struct
from binascii import *
obj = wave.open('data.wav', 'r')
frames = obj.getnframes()
frames_data = obj.readframes(frames).hex()
bin_data = ''
for idx in range(0, len(frames_data), 4):
data = frames_data[idx:idx+4]
data = data[2:] + data[:2]
if int(data, 16) <= 20000:
bin_data += '0'
elif int(data, 16) > 20000 and int(data, 16) <= 32000:
bin_data += '1'
elif int(data, 16) > math.pow(2, 15):
overflow_data = math.pow(2, 15) - (int(data, 16) - math.pow(2, 15))
if overflow_data > 20000 and overflow_data <= 32000:
bin_data += '1'
elif overflow_data <= 20000:
bin_data += '0'
hex_data = ''
for idx in range(0, len(bin_data), 8):
hex_data += '{:02x}'.format(int(bin_data[idx:idx+8], 2))
with open('data', 'wb') as f1:
f1.write(unhexlify(hex_data))
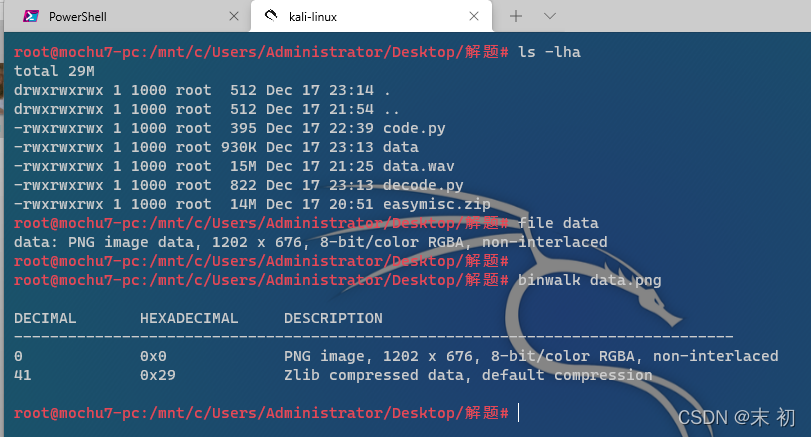
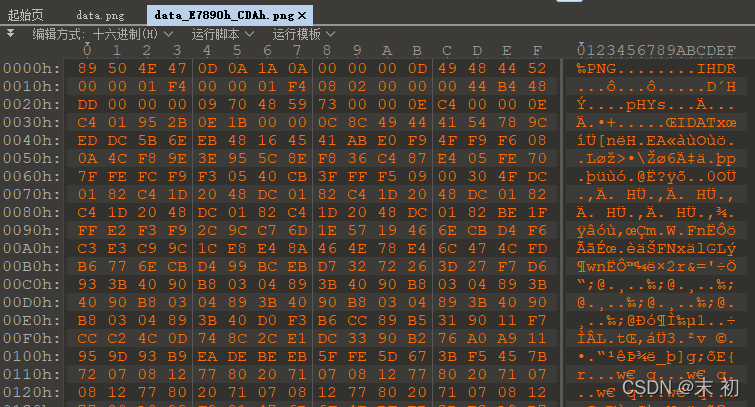
得到一张PNG图片,从binwalk分析来看,档案尾附加了内容
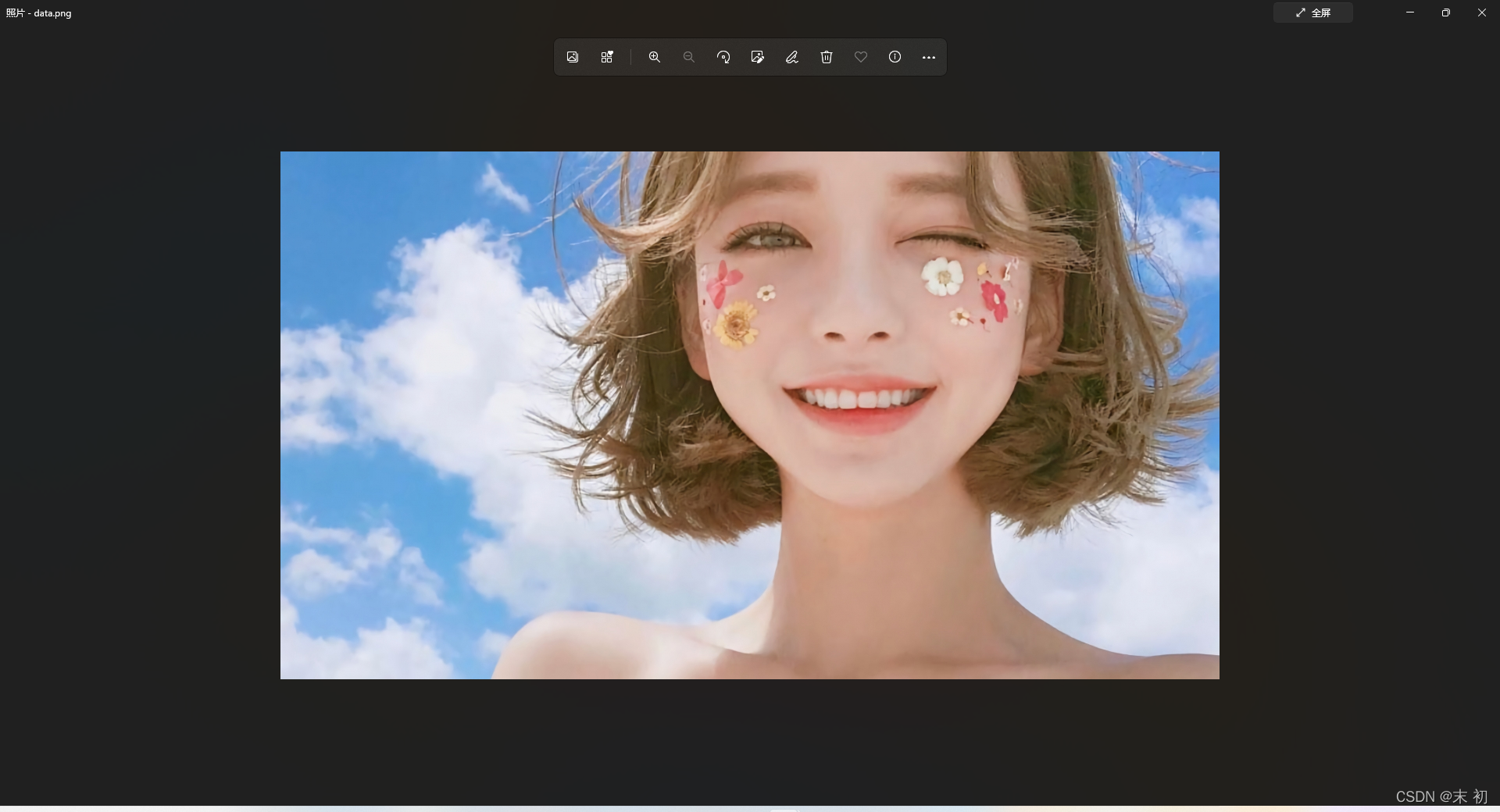
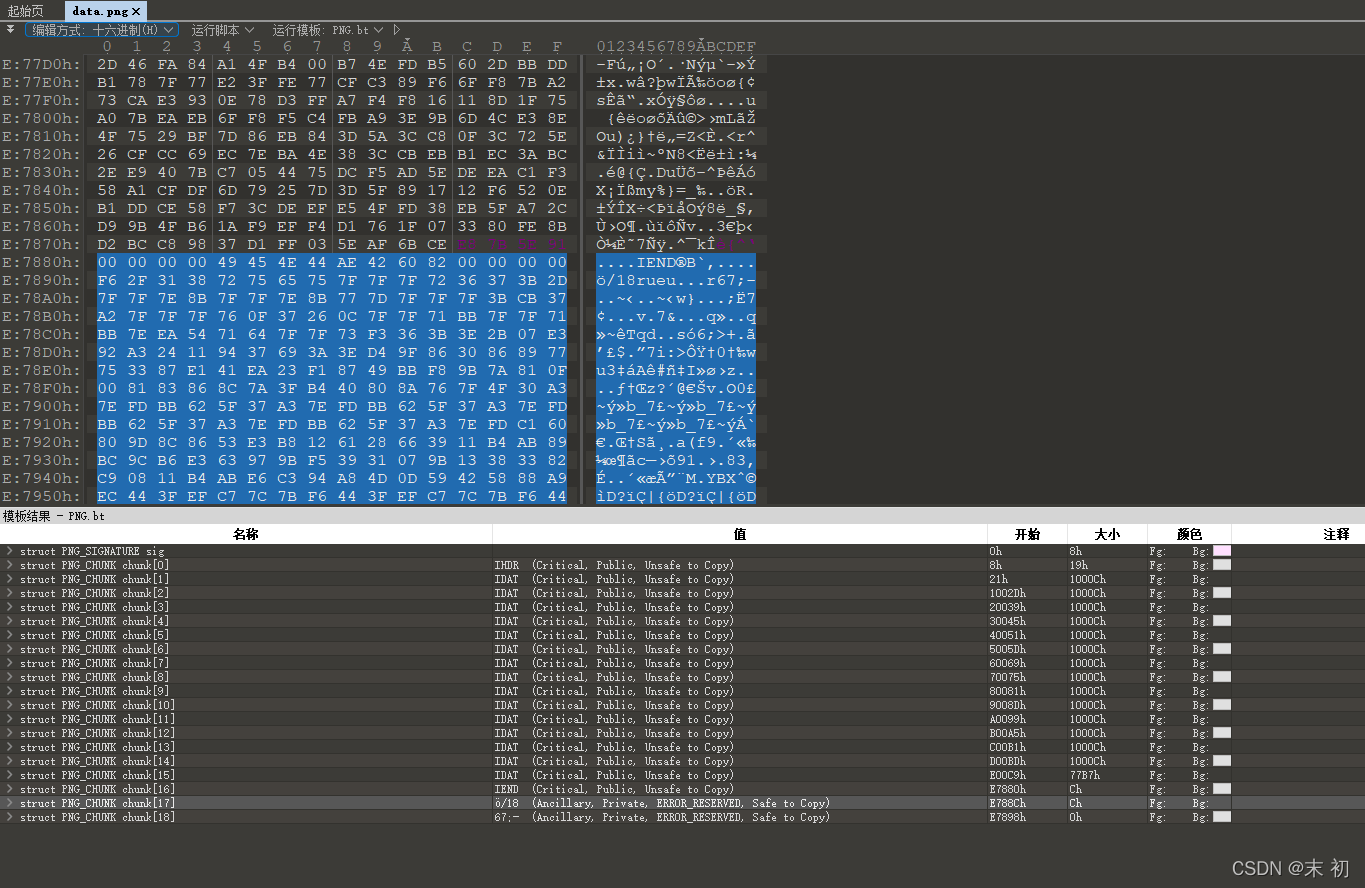
附加内容直接看不出来什么,尝试对图片分析,发现存在无密码的LSB隐写
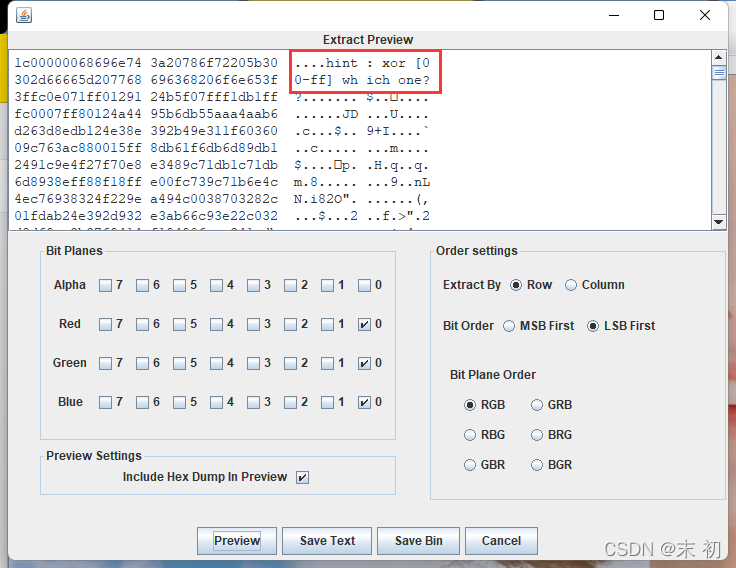
hint: xor [00-ff] which one?
提示异或一个范围内的一个值,即可猜测附加的资料是经过异或的;可以尝试提取开头的几个位元组进行异或看看结果是否为常见档案型别的档案头;Python简单处理即可
head_bytes = 'F6 2F 31 38'
for n in range(0xff):
hex_data = head_bytes.split(" ")
xor_data = ''
for data in hex_data:
data = int(data, 16) ^ n
xor_data += ' {:02x}'.format(data)
print("XOR {:02x}: {}".format(n, xor_data))
从结果中可以发现出现了PNG档案头
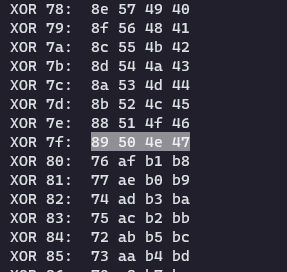
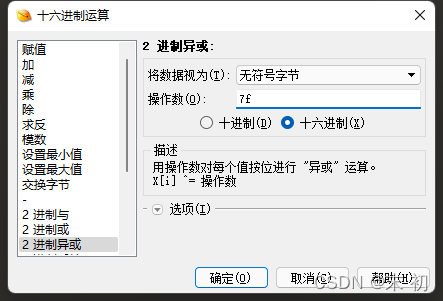
将附加资料提取出来,使用010 Editor打开工具->十六进制运算->二进制异或
得到一张二维码,扫描即可得到flag
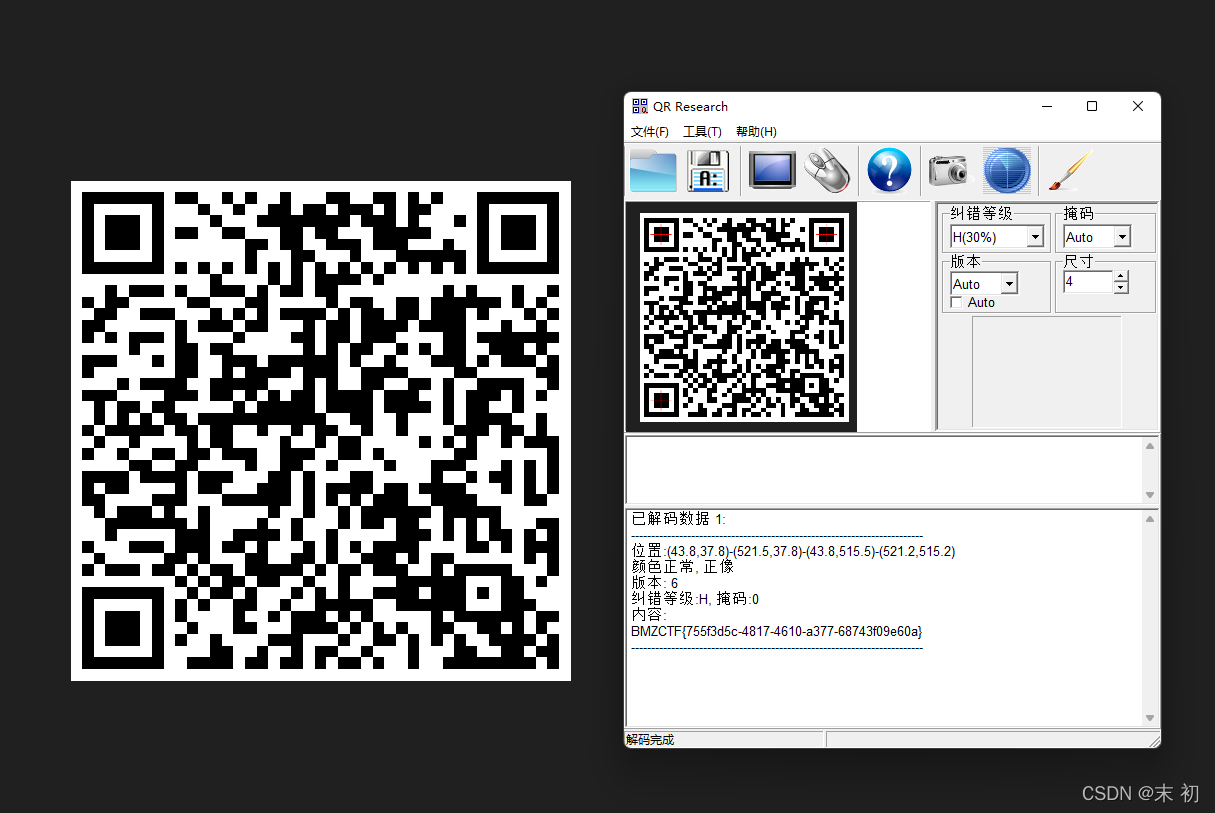
BMZCTF{755f3d5c-4817-4610-a377-68743f09e60a}








0 评论