我在抓取这个网站的表格时遇到了问题,我应该得到标题,但我得到了
AttributeError: 'NoneType' object has no attribute 'tbody'
我对网络抓取有点陌生,所以如果你能帮助我,那就太好了
import requests
from bs4 import BeautifulSoup
URL = "https://www.collincad.org/propertysearch?situs_street=Willowgate&situs_street_suffix" \
"=&isd[]=any&city[]=any&prop_type[]=R&prop_type[]=P&prop_type[]=MH&active[]=1&year=2021&sort=G&page_number=1"
s = requests.Session()
page = s.get(URL)
soup = BeautifulSoup(page.content, "lxml")
table = soup.find("table", id="propertysearchresults")
table_data = table.tbody.find_all("tr")
headings = []
for td in table_data[0].find_all("td"):
headings.append(td.b.text.replace('\n', ' ').strip())
print(headings)
uj5u.com热心网友回复:
怎么了?
注意: 总是先看看你的汤 - 这就是真相。内容可能总是与开发工具中的视图略有不同。
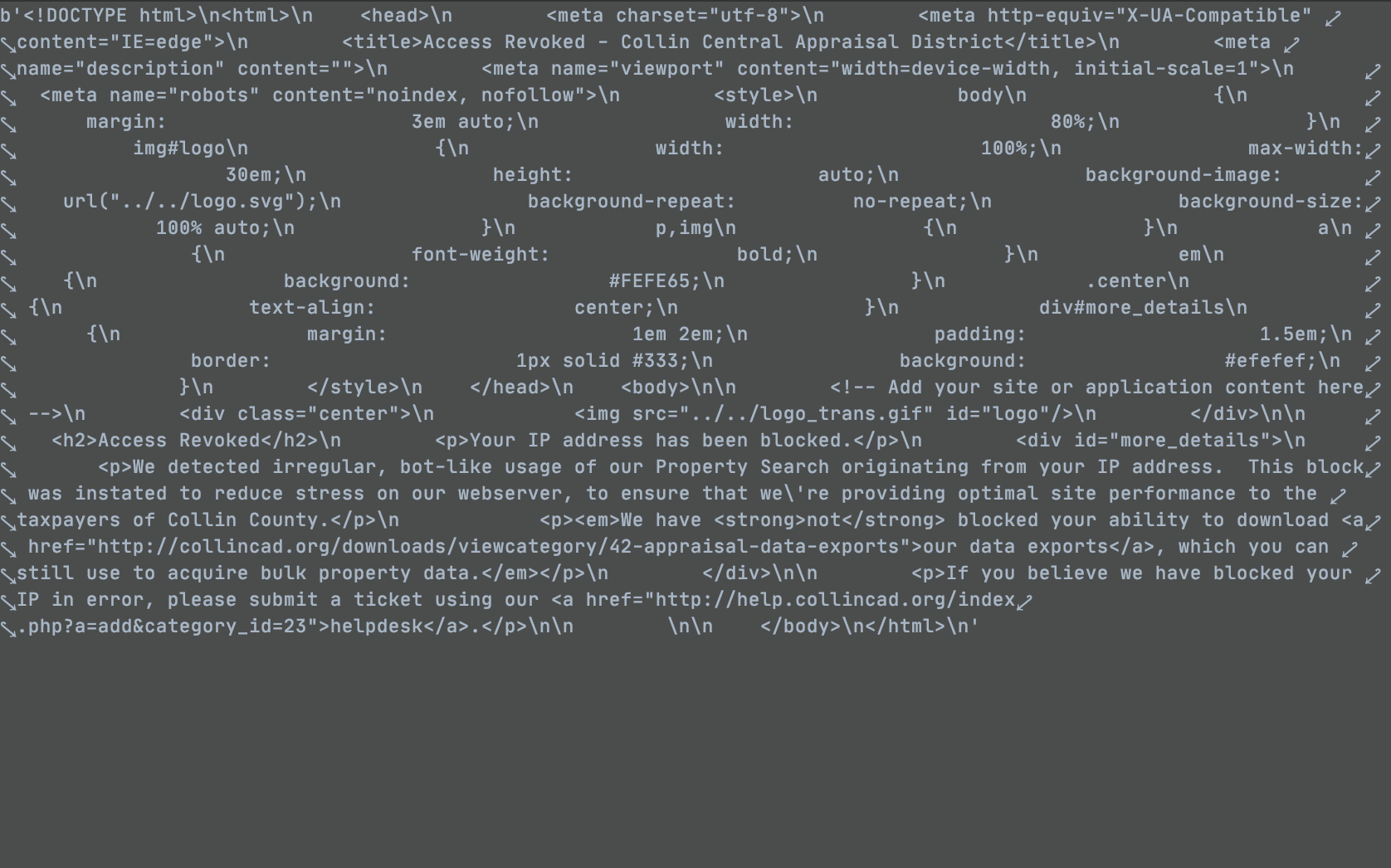
访问权限被撤销
您的 IP 地址已被阻止。
我们检测到来自您的 IP 地址的对我们的属性搜索的不规则、类似机器人的使用。设定此块是为了减轻我们的网络服务器的压力,以确保我们为科林县的纳税人提供最佳的网站性能。
我们 没有阻止您下载
您应该在请求中添加一些标头,因为该网站阻止了您的请求。在您的特定情况下,添加一个就足够了
User-Agent:import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36' } URL = "https://www.collincad.org/propertysearch?situs_street=Willowgate&situs_street_suffix" \ "=&isd[]=any&city[]=any&prop_type[]=R&prop_type[]=P&prop_type[]=MH&active[]=1&year=2021&sort=G&page_number=1" s = requests.Session() page = s.get(URL, headers=headers) soup = BeautifulSoup(page.content, "lxml") table = soup.find("table", id="propertysearchresults") table_data = table.tbody.find_all("tr") headings = [] for td in table_data[0].find_all("td"): headings.append(td.b.text.replace('\n', ' ').strip()) print(headings)如果添加标题,您仍然会出现错误,但在行中:
headings.append(td.b.text.replace('\n', ' ').strip())你应该把它改成
headings.append(td.text.replace('\n', ' ').strip())因为
td并不总是有b.













0 评论