(一)作业要求
advertising.csv档案(档案私聊可取)是某商品的广告推广费用(单位为元)和销售额资料(单位为千元),其中每行代表每一周的广告推广费用(包含微信、微博和其他型别三种广告费用)和销售额,若在未来的某两周,将各种广告投放金额按如下分配,请预测对应的商品销售额:
(1)微信:100,微博:100,其他型别:100
(2)微信:200,微博:100,其他型别:50
另外,请提交对应的代码,若有对应的说明档案,也请提交,
(二)作业内容
对于这个实验,是机器学习中最常见的一类回归问题,通过已有的资料,判断对某一资料的影响,我将依次按照下列顺序进行,
-
对表格中基本信息的观察:
当我们打开Excel档案的时候,得到的是一系列的资料,一共201行,4列;第一行是标签的信息,包括微信、微博、其它和销售额(前三个是投放),底下的二百行是不同的投放量和对应的销售额,如此看来不是很直观,我们可以通过matplotlib将资料可视化出来,另外,为了使绘制的图更好看,我还使用了seaborn库中的set函式,
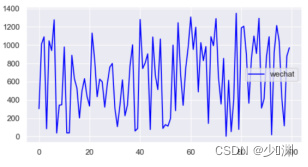
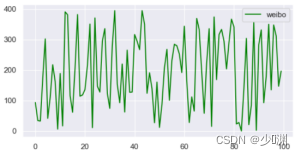
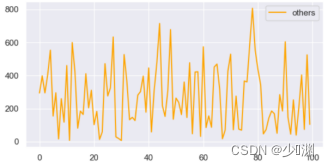
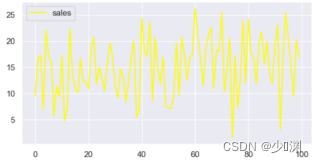
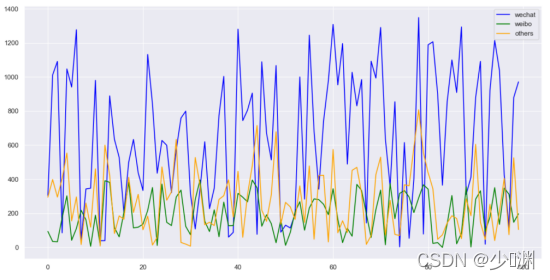
因为我想使用线性回归的方法对样本进行估计,所以需要观测三种投放量之间和销售额是否存在线性关系,简单直观的方式可以是使用散点图在二维平面中对资料进行可视化表示,于是我们再通过plt.scatter()绘制散点图:
观察影像我们得出的结论是:①每种投放量都是在一定区域内浮动的,没有一个准确的定值,且相对而言微信投放量最大、其他投放次之、微博投放最少②销售额大体上随着三种投放的增加而增加,并且在5~25(千元)内浮动③观察散点图中销售额和各投放量的关系我们可以得到:微信投放和销售额的线性关系最强,其他投放和销售额的线性关系最弱,但是都满足,随着投放量的增长,销售额也随之增长,
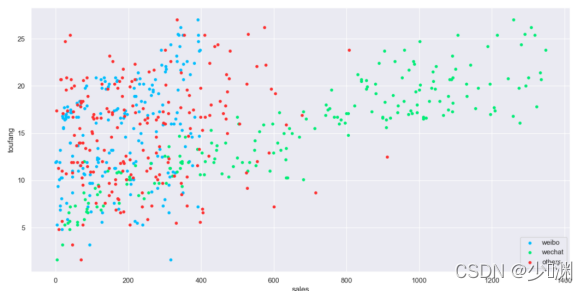
2、分别对各投放量的销售额进行估计
上面的散点图告诉我们,投放量和销售额大致满足线性关系,那我们分别用微信投放量、微博投放量、其他投放量和三者总投放量对销售额进行预测,
- 用三种总投放量预测销售额
首先,我们通过pandas库读取csv档案并分别获取投放量和销售额的信息,然后我们通过sklearn.model_selection中的train_test_split将资料分割为测验集和训练集,在此我定义测验集的比例为0.1,因为我首先选择使用最简单的线性回归进行预测,所以我们还要汇入LinearRegression并且通过fit函式对模型进行训练,训练之后,为了检测结果的耦合程度,我们利用测验集的X_test通过predict函式产生一个预测的y_predict,然后和真实值y_test进行比较,为了使结果更形象,我们可以绘制一个折线图,并且通过sklearn库中封装好的score函式对模型进行评分,然后呈现出来,
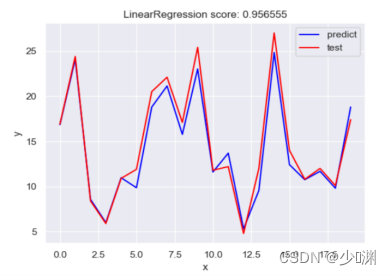
评分是0.957,再看影像,大体上还是令人满意的,于是我们根据所给的投放量:
① 微信:100,微博:100,其他型别:100
② 微信:200,微博:100,其他型别:50
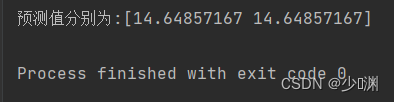
再次进行预测,预测的方法很简单,直接将所给的资料装到一个DataFrame型别的阵列中,然后以这个阵列作为x_test,输出测验的predict即可,

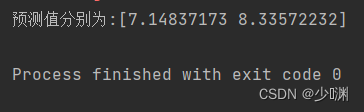
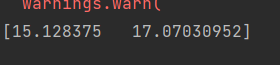
预测值分别为7.148千元和8.336千元,我查看了表中类似的资料,结果大体上正确,
2、通过微信、微博、其他投放进行预测
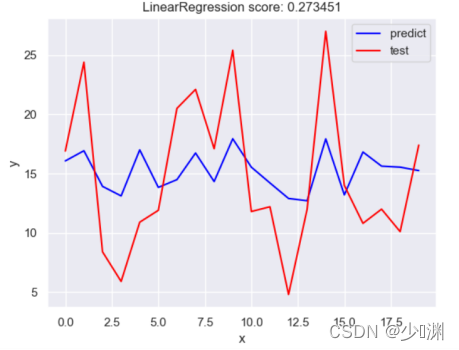
其实这部分并没有什么太大的意义,只是我希望看到三种投放量哪个对销售额影响大、哪些影响小,对于这部分,具体代码和上面几乎一模一样,就是把测验和训练用的资料限定在微信投放量上,这样得到的预测曲线和预测结果如下:
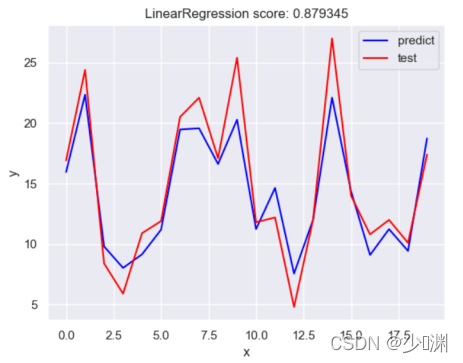
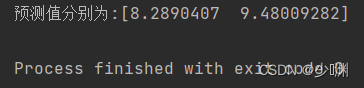
(微信)
![]()
(微博)
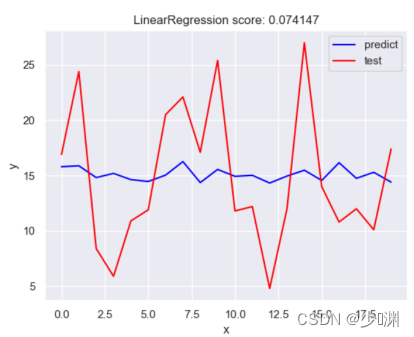
(其它)
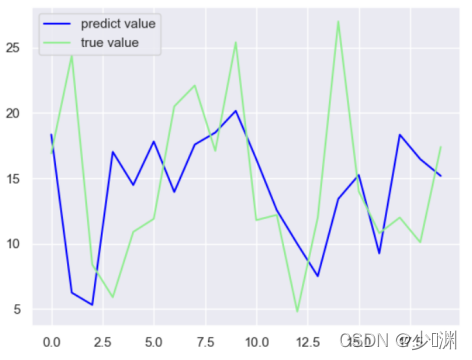
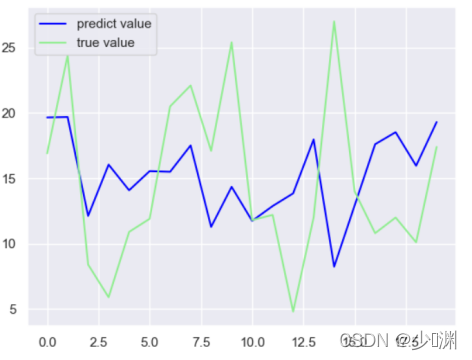
我们发现除了微信投放和销售额曲线较为拟合外,其他两种投放方式和实际值相去甚远,也就看出不可以使用线性回归对这两种投放量进行预测,
观察到如此大的差异后,我们再用回归系数观测一下三种投放量对销售额的影响程度:我们可以通过seaborn库中的heatmap热力图来绘制相关性矩阵热力图,比较各个变量之间的相关性:

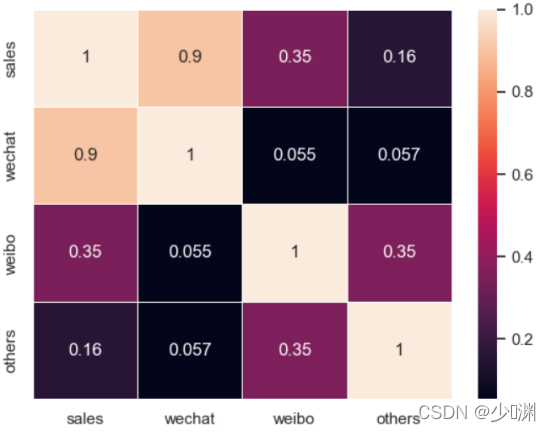
颜色越浅代表相关性越大,图中可以看出微信对销售额的影响最大,其他对销售额的影响最小,为了让图反应出的信息更加直观,我们可以直接打印出相关性的排名如下:
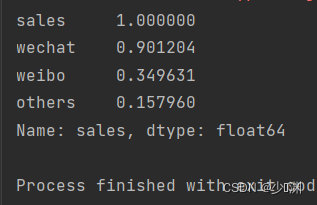
相关性最大的是微信,同时根据回归系数的性质我们知道,回归系数越大,说明x对y的影响越大,所以我们也可以通过查看他们的回归系数来判断三种投放对销售额的影响程度,
3、使用多项式回归预测销售额
在上面的程序中我发现对于微博投放和其他投放而言,从散点图可以看出它们和销售额并不完全服从线性回归,在观看了北京理工大学python机器学习应用部分章节之后,我了解到对于线性不拟合的资料,我们也可以通过多项式拟合的方式预测资料,
下面我将以多项式拟合查看和销售额的拟合程度并且预测在给定条件下的销售额的值,
我们将PolynomialFeatures的degree属性设定为2,也就是关于微信投放量信息X的二次多项式,然后我们选择一百八十个资料进行训练,并且打印出训练后曲线和原散点图的影像:
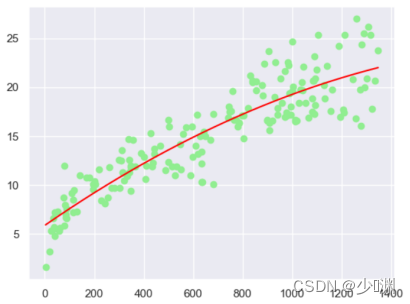
结果非常的amazing啊,比线性回归的的一条直线要拟合不少,然后我们再拿出20个资料进行预测,看看大概的匹配程度如何:
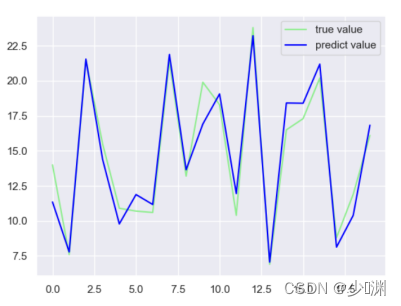
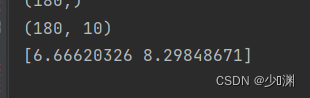
可以看到结果还是差强人意(大体上使人满意)的,两种投放方式得出的结果和第一次得出的结果还是挺接近的,
4、使用随机森林预测销售额
我感觉单纯的线性回归还是满足不了我,我就又在网上找其他的回归方法,最终决定用随机森林的方法再次预测销售额,
随机森林的定义我就不班门弄斧了,下面直接进行操作,依然分别进行三种投放同时作用和分别作用造成的销售额的变化情况,
- 三种投放同时作用
其实我感觉各种回归方法虽然很难,但是基本的运用还是很容易的,只是需要反复使用fit和predict方法罢了,然后通过plot函式打出来,结果如下:
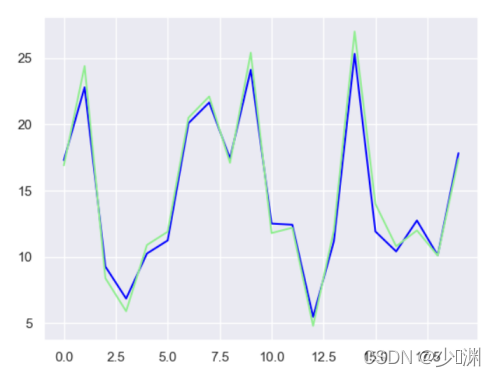
可以看到拟合程度非常的高!但是其实我也不知道原理,只是发现通过这个方法只需要十几行代码就可以让它的拟合度如此之高!我们趁热打铁,把预测结果的值算出来:
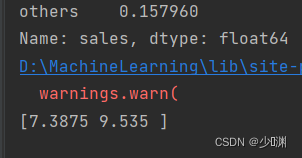
可以发现和我们最初使用线性回归的结果十分接近,并且应该更准确,
2、只有微信投放
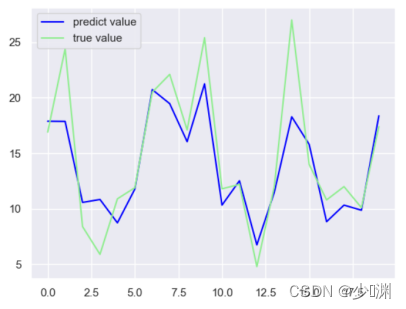
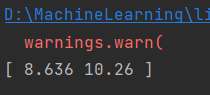
3、只有微博投放
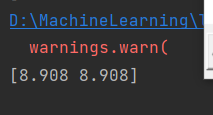
4、只有其他投放








0 评论