今天的爬虫有点特别,先爬取文本,然后base64译码,然后再存盘至文本字典内
点个赞留个关注吧!!
首先我们需要爬取网站链接
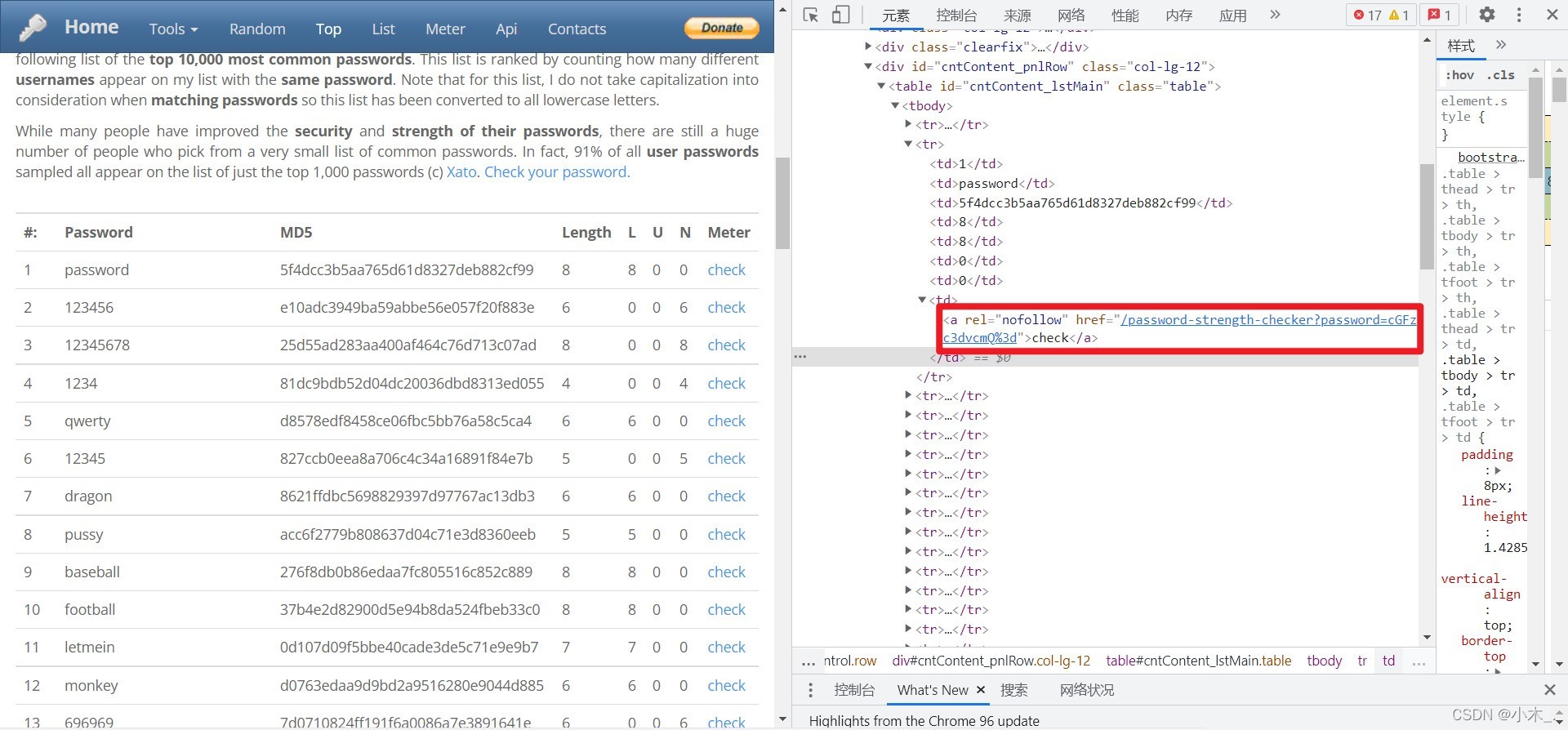
代码如下:
爬取后我们只要password=内容,只要内容,不需要链接,所以我们这里使用了
res_6 = re.findall('password=(.*)', e) #爬取密码链接password=?# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
import requests
r = requests.get(f'https://www.passwordrandom.com/most-popular-passwords/page/1') #要爬取的网站链接
html = r.content
soup = BeautifulSoup(html,'html.parser') #html.parser是决议器
div_people_list = soup.find_all('table', attrs={'class': 'table'})
for a in div_people_list:
for b in a.find_all('td'):
for c in b.find_all('a', attrs={'rel': 'nofollow'}):
e = c['href'] #链接
res_6 = re.findall('password=(.*)', e) #爬取密码链接password=?
ty = res_6[0] #读取字典的第一位
tu = ty.replace("%3d", "").strip() #去除文本的%3d
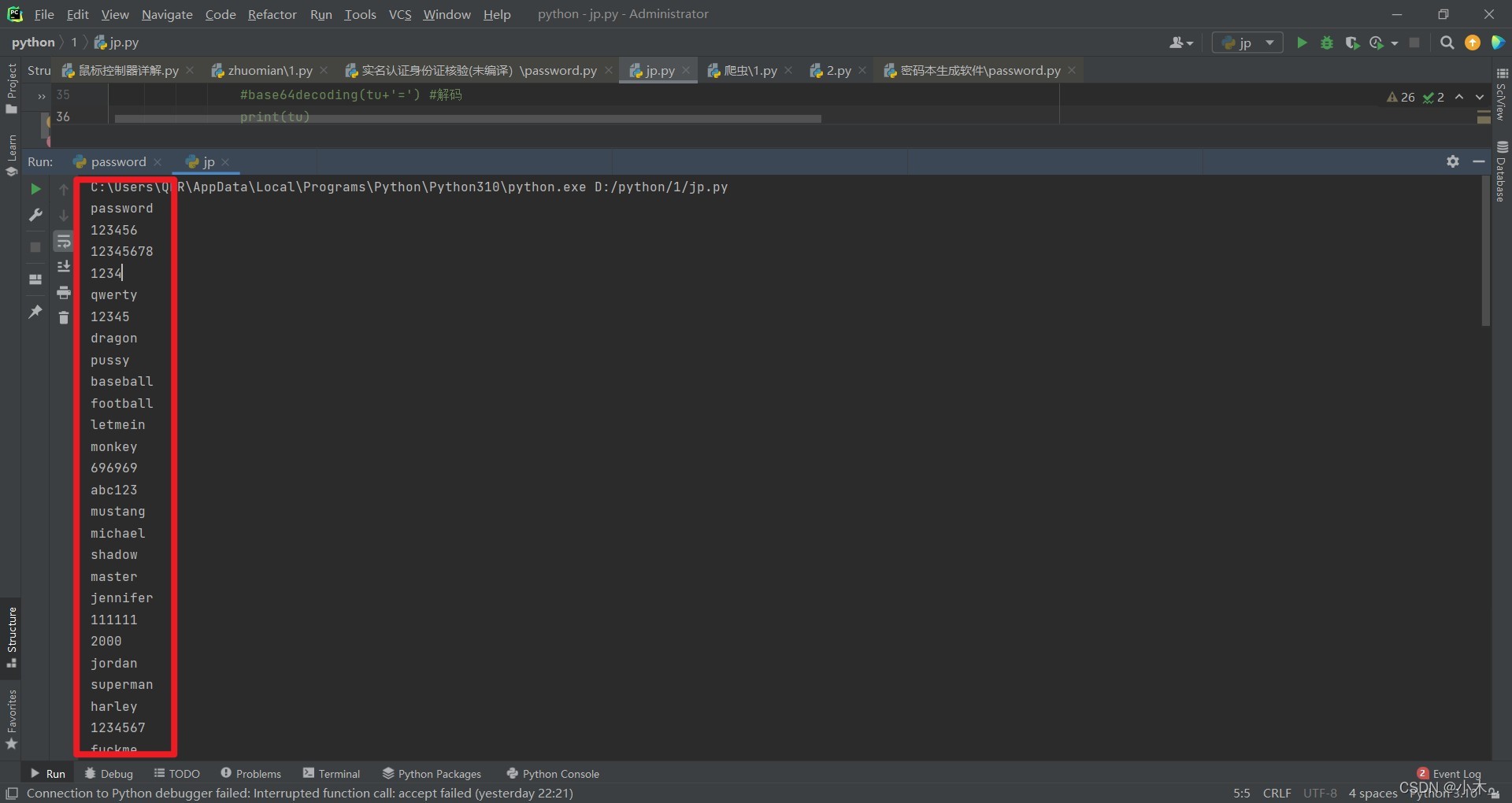
print(tu)爬取后是这样的,这是没有译码的
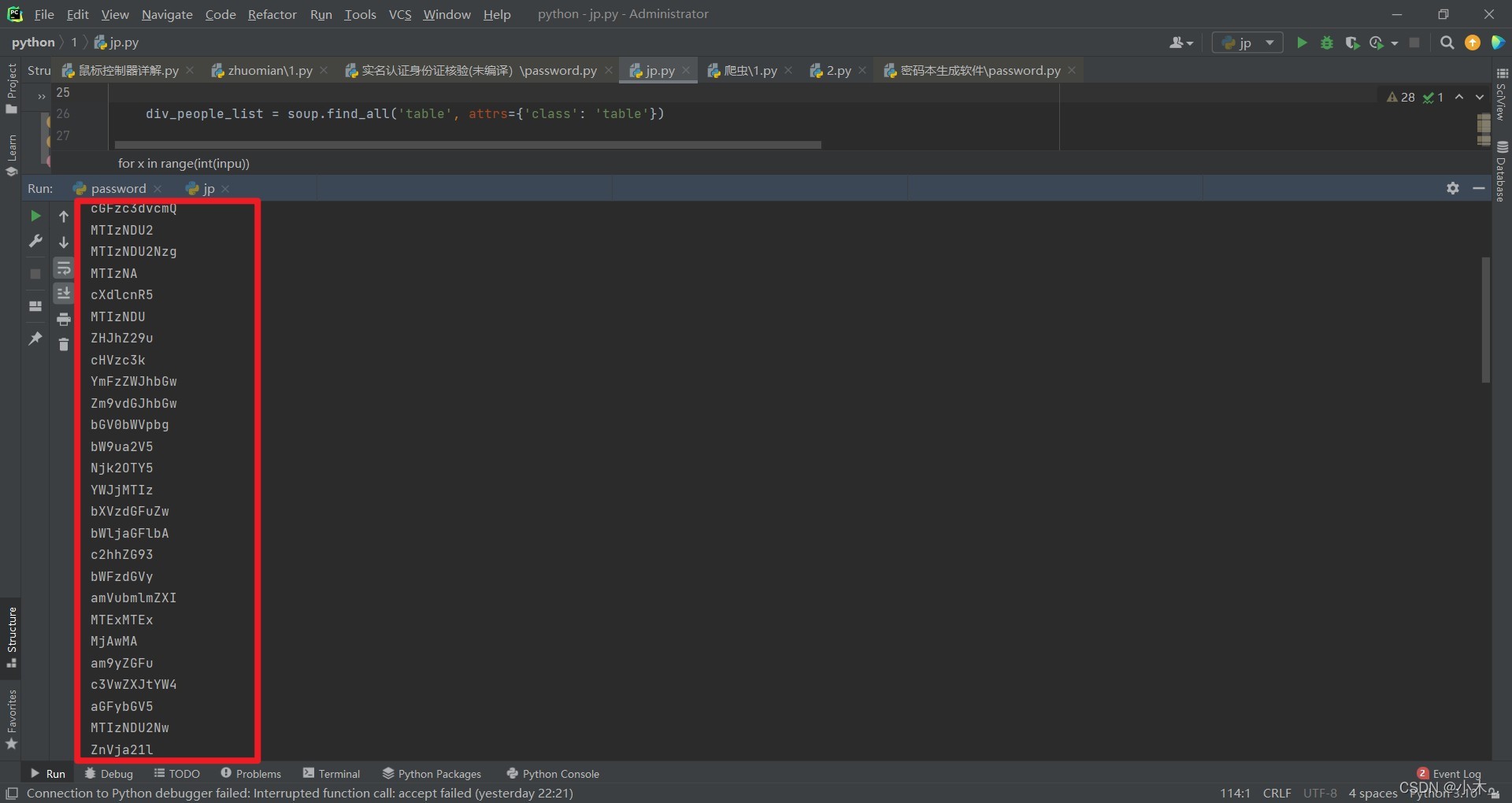
现在我们开始译码,因为译码是会有问题的,所有我中间译码的时候又加了一道检测程序,主要是检测有没有被译码,如果没有被译码,则添加《=》并再次译码,这样就能全部译码了
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
import base64
import requests
f = open('爬取档案.txt','a+',encoding='UTF-8') #写入档案
#base64译码
def base64decoding(src):
try:
while True:
src = base64.b64decode(src).decode() #译码
except Exception:
if src.endswith('=') == True: #判断是否译码成功
ty = f'{src}=' #再次添加=并译码
base64decoding(ty) #再次
else:
print(src)
r = requests.get(f'https://www.passwordrandom.com/most-popular-passwords/page/1') #要爬取的网站链接
html = r.content
soup = BeautifulSoup(html,'html.parser') #html.parser是决议器
div_people_list = soup.find_all('table', attrs={'class': 'table'})
for a in div_people_list:
for b in a.find_all('td'):
for c in b.find_all('a', attrs={'rel': 'nofollow'}):
e = c['href'] #链接
res_6 = re.findall('password=(.*)', e) #爬取密码链接password=?
ty = res_6[0] #读取字典的第一位
tu = ty.replace("%3d", "").strip() #去除文本的%3d
base64decoding(tu+'=') #译码已译码
现在我们需要写入档案,我把代码又添加了一点
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
import base64
import requests
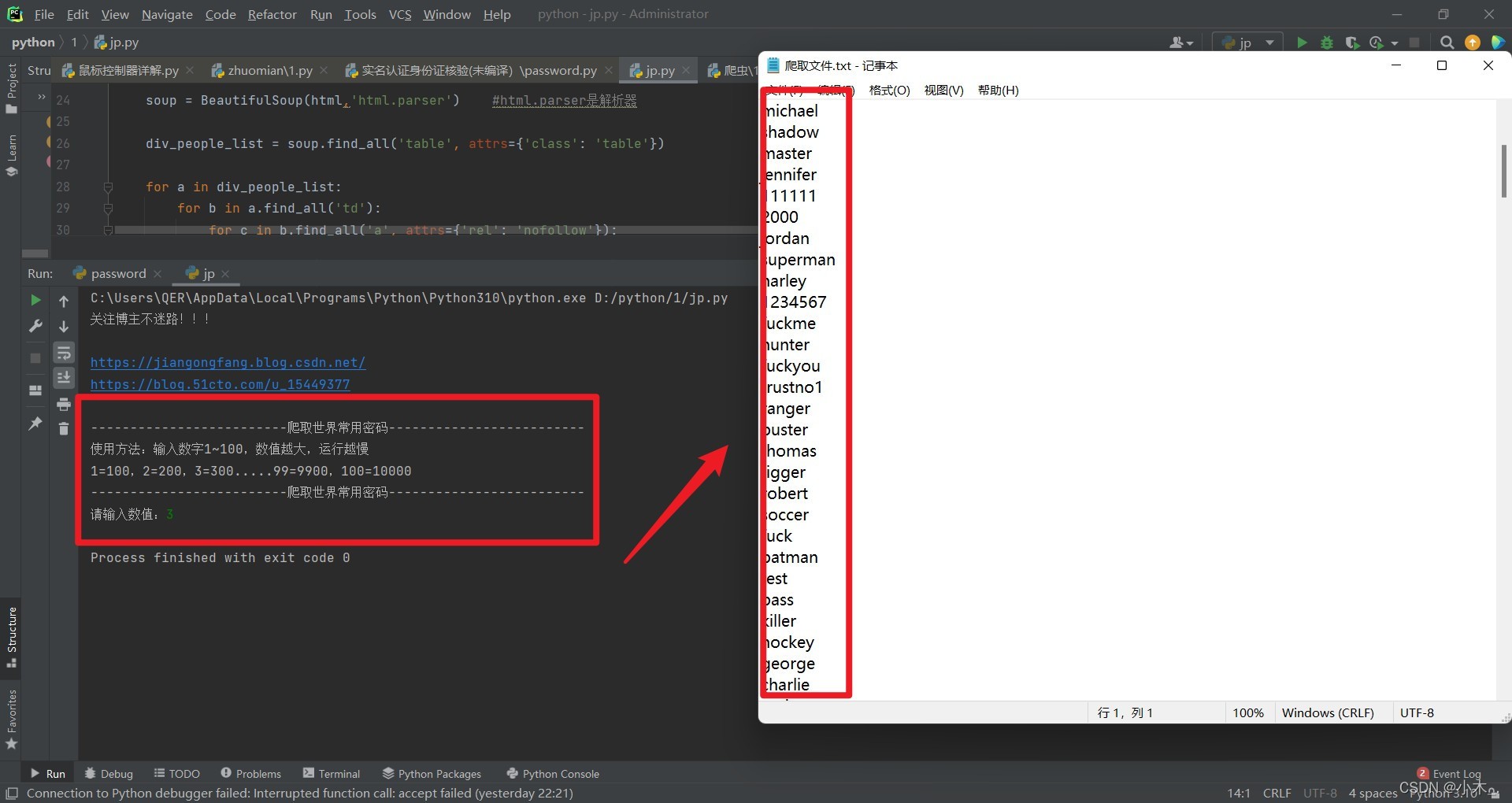
inpu = input('关注博主不迷路!!!\n\nhttps://jiangongfang.blog.csdn.net/\nhttps://blog.51cto.com/u_15449377\n\n-------------------------爬取世界常用密码-------------------------\n使用方法:输入数字1~100,数值越大,运行越慢\n1=100,2=200,3=300.....99=9900,100=10000\n-------------------------爬取世界常用密码------------------------- \n请输入数值:')
f = open('爬取档案.txt','a+',encoding='UTF-8') #写入档案
#base64译码
def base64decoding(src):
try:
while True:
src = base64.b64decode(src).decode() #译码
except Exception:
if src.endswith('=') == True: #判断是否译码成功
ty = f'{src}=' #再次添加=并译码
base64decoding(ty) #再次
else:
f.write(src+'\n') #写入档案内
for x in range(int(inpu)):
r = requests.get(f'https://www.passwordrandom.com/most-popular-passwords/page/{x}') #要爬取的网站链接
html = r.content
soup = BeautifulSoup(html,'html.parser') #html.parser是决议器
div_people_list = soup.find_all('table', attrs={'class': 'table'})
for a in div_people_list:
for b in a.find_all('td'):
for c in b.find_all('a', attrs={'rel': 'nofollow'}):
e = c['href'] #链接
res_6 = re.findall('password=(.*)', e) #爬取密码链接password=?
ty = res_6[0] #读取字典的第一位
tu = ty.replace("%3d", "").strip() #去除文本的%3d
base64decoding(tu+'=') #译码其中里面的数值控制着链接,填1就相当于爬取100个密码,2就是200个,30就是3000个,当然,最高位100,填的越高,计算机运行越慢,配置低的尽量填50以下,太高怕你们计算机受不了
完整代码:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
import base64
import requests
inpu = input('关注博主不迷路!!!\n\nhttps://jiangongfang.blog.csdn.net/\nhttps://blog.51cto.com/u_15449377\n\n-------------------------爬取世界常用密码-------------------------\n使用方法:输入数字1~100,数值越大,运行越慢\n1=100,2=200,3=300.....99=9900,100=10000\n-------------------------爬取世界常用密码------------------------- \n请输入数值:')
f = open('爬取档案.txt','a+',encoding='UTF-8') #写入档案
#base64译码
def base64decoding(src):
try:
while True:
src = base64.b64decode(src).decode() #译码
except Exception:
if src.endswith('=') == True: #判断是否译码成功
ty = f'{src}=' #再次添加=并译码
base64decoding(ty) #再次
else:
f.write(src+'\n') #写入档案内
for x in range(int(inpu)):
r = requests.get(f'https://www.passwordrandom.com/most-popular-passwords/page/{x}') #要爬取的网站链接
html = r.content
soup = BeautifulSoup(html,'html.parser') #html.parser是决议器
div_people_list = soup.find_all('table', attrs={'class': 'table'})
for a in div_people_list:
for b in a.find_all('td'):
for c in b.find_all('a', attrs={'rel': 'nofollow'}):
e = c['href'] #链接
res_6 = re.findall('password=(.*)', e) #爬取密码链接password=?
ty = res_6[0] #读取字典的第一位
tu = ty.replace("%3d", "").strip() #去除文本的%3d
base64decoding(tu+'=') #译码








0 评论