利用Python多执行绪爬了5000多部最新电影下载链接,废话不多说~
让我们愉快地开始吧~
开发工具
Python版本:3.6.4
相关模块:
requests模块;
re模块;
csv模块;
以及一些Python自带的模块,
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可,
很多人学习蟒蛇,不知道从何学起, 很多人学习python,掌握了基本语法之后,不知道在哪里寻找案例上手, 很多已经做了案例的人,却不知道如何去学习更多高深的知识, 那么针对这三类人,我给大家提供一个好的学习平台,免费获取视频教程,电子书,以及课程的源代码! QQ群:101677771 欢迎加入,一起讨论一起学习
bs = BeautifulSoup(html, "html.parser")
b = bs.findAll(class_="co_content8")
b = b[0].findAll(class_="ulink")拿到链接之后,接下来就是继续访问这些链接,然后拿到电影的下载链接
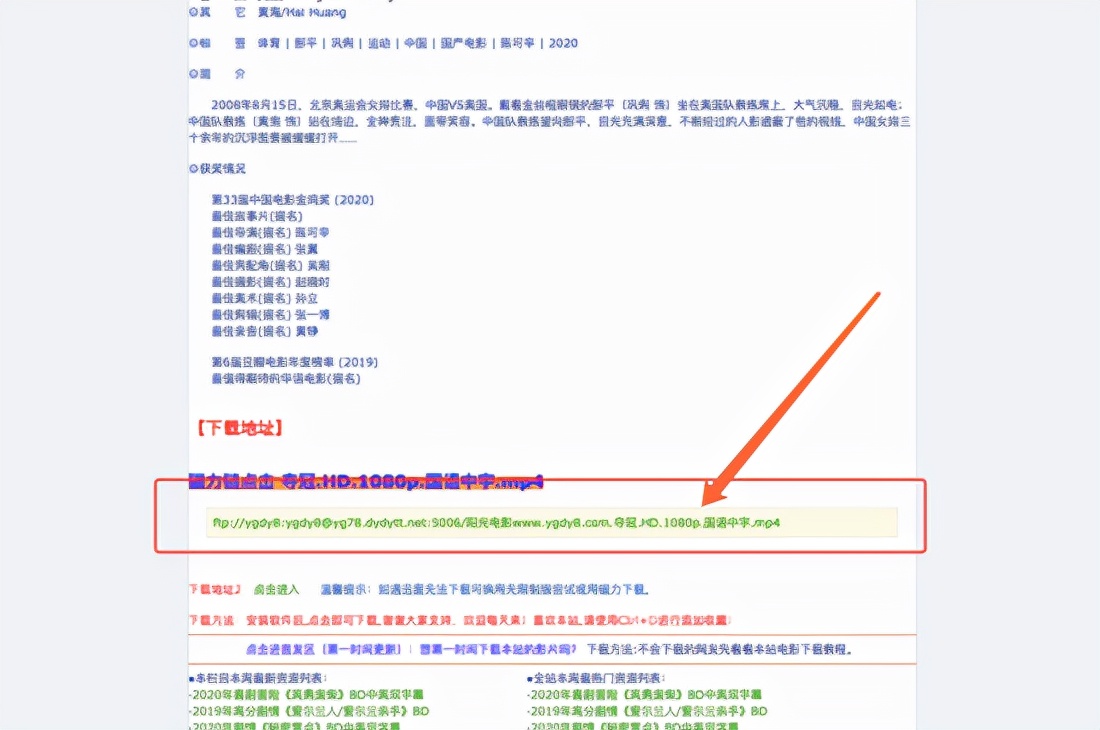
bs1 = BeautifulSoup(html1, "html.parser")
b1 = bs1.find("tbody").find_next("td").find_next("a")
download_url = b1.get("href")但是这里还是有很多的小细节,例如我们需要拿到电影的总页数,其次这幺多的页面,一个执行绪不知道要跑到什么时候,所以我们首先先拿到总页码,然后用多执行绪来进行任务的分配
我们首先先拿到总页码,然后用多执行绪来进行任务的分配
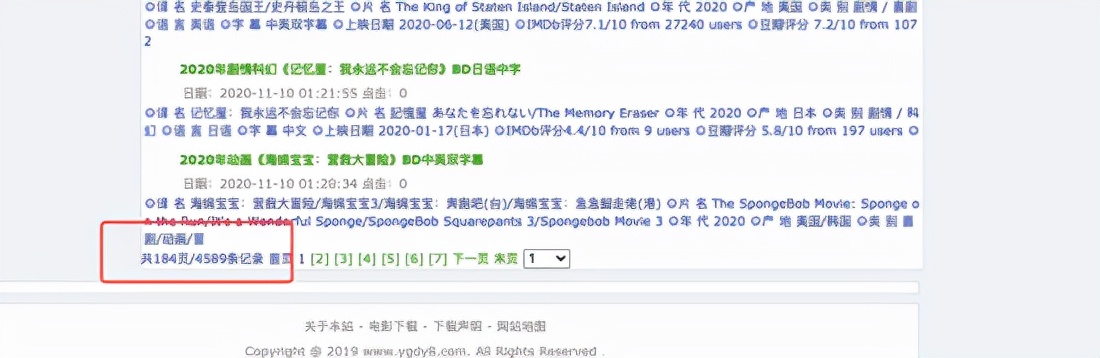
总页数其实我们用re正则来获取
def get_total_page(url):
r = requests.get(url=url,headers=headers)
r.encoding = 'gb2312'
pattern = re.compile(r'(?<=页/)\d+')
t = pattern.findall(r.text)
return int(t[0])爬取的内容存取到csv,也可以写个函式来存取
def wirte_into_csv(name,down_url):
f = open('最新电影.csv', 'a+', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow([name,down_url])
f.close()本文原始码滴我666
开启4个行程来下载链接
total_page = get_total_page("https://www.ygdy8.com/html/gndy/oumei/list_7_1.html")
total_page = int(total_page/25+1)
end = int(total_page/4)
try:
_thread.start_new_thread(run, (1, end))
_thread.start_new_thread(run, (end+1, end*2))
_thread.start_new_thread(run, (end*2 + 1, end * 3))
_thread.start_new_thread(run, (end*3 + 1, end * 4))
except:
print("Error: 无法启动执行绪")
while(1):
pass














0 评论