整理了一份大厂常考面试题,这份pdf包括 Java基础、Java并发、JVM、MySQL、Redis、Spring、MyBatis、Kafka、设计模式等面试题,分享给大家,
下载地址:百度云链接:https://pan.baidu.com/s/1XHT4ppXTp430MEMW2D0-Bg 提取码: s3ab
Redis 底层的基础资料结构有哪些?
答案:
-
字符串,没有采用C语言的传统字符串,而是自己实作的一个简单动态字符串SDS的抽象型别,并保存了长度信息,
-
链表(linkedlist),双向无环链表结构,每个链表的节点由一个listNode结构来表示,每个节点都有前置和后置节点的指标
-
字典(hashtable),保存键值对的抽象资料结构,底层使用hash表,每个字典带有两个hash表,供平时使用和rehash时使用,
-
跳跃表(skiplist),跳跃表是有序集合的底层实作之一,redis跳跃表由zskiplist和zskiplistNode组成,zskiplist用于保存跳跃表 信息(表头、表尾节点、?度等),zskiplistNode用于表示表跳跃节点,每个跳跃表的层高都是1- 32的随机数,在同一个跳跃表中,多个节点可以包含相同的分值,但是每个节点的成员物件必须是唯一的,节点按照分值大小排序,如果分值相同,则按照成员物件的大小排序,
-
整数集合(intset),用于保存整数值的集合抽象资料结构,不会出现重复元素,底层实作为阵列,
-
压缩串列(ziplist),为节约存储器而开发的顺序性资料结构,可以包含多个节点,每个节点可以保存一个字节阵列或者整数值,
Redis 支持哪些资料型别?
答案:五种常用资料型别:String、Hash、Set、List、SortedSet,三种特殊的资料型别:Bitmap、HyperLogLog、Geospatial,其中Bitmap 、HyperLogLog的底层都是 String 资料型别,Geospatial 底层是 Sorted Set 资料型别,
-
字符串物件string:int整数、embstr编码的简单动态字符串、raw简单动态字符串
-
串列物件list:ziplist、linkedlist
-
哈希物件hash:ziplist、hashtable
-
集合物件set:intset、hashtable
-
有序集合物件zset:ziplist、skiplist
Redis 常用的 5 种资料结构和应用场景?
答案:
-
String:快取、计数器、分布式锁等
-
List:链表、队列、微博关注人时间轴串列等
-
Hash:用户信息、Hash 表等
-
Set:去重、赞、踩、共同好友等
-
Zset:访问量排行榜、点击量排行榜等
为什么采用单执行绪?
答案:官方回复,CPU不会成为Redis的制约瓶颈,Redis主要受存储器、网络限制,例如,在一个普通的 Linux 系统上,使用pipelining 可以每秒传递 100 万个请求,所以如果您的应用程序主要使用 O(N) 或 O(log(N)) 命令,则几乎不会使用太多 CPU,属于IO密集型系统,
Redis 6.0 之后又改用多执行绪呢?
答案:Redis的多执行绪主要是处理资料的读写、协议决议,执行命令还是采用单执行绪顺序执行,
主要是因为redis的性能瓶颈在于网络IO而非CPU,使用多执行绪进行一些周边预处理,提升了IO的读写效率,从而提高了整体的吞吐量,antirez 在 RedisConf 2019 分享时提到,Redis 6 引入的多执行绪 IO 对性能提升至少一倍以上,
过期键Key 的洗掉策略有哪些?
答案:有3种过期洗掉策略,惰性洗掉、定期洗掉、定时洗掉
-
惰性洗掉,使用key时才进行检查,如果已经过期,则洗掉,缺点:过期的key如果没有被访问到,一直无法洗掉,一直占用存储器,造成空间浪费,
-
定期洗掉,每隔一段时间做一次检查,洗掉过期的key,每次只是随机取一些key去检查,
-
定时洗掉,为每个key设定过期时间,同时创建一个定时器,一旦到期,立即执行洗掉,缺点:如果过期键比较多时,占用CPU较多,对服务的性能有很大影响,
如果Redis的存储器空间不足,淘汰机制?
答案:
-
volatile-lru:从已设定过期时间的key中,移出最近最少使用的key进行淘汰
-
allkeys-lru:当存储器不足以容纳新写入资料时,在键空间中,移除最近最少使用的key(这个是最常用的)
-
volatile-ttl:从已设定过期时间的key中,移出将要过期的key
-
volatile-random:从已设定过期时间的key中,随机选择key淘汰
-
allkeys-random:从key中随机选择key进行淘汰
-
no-eviction:禁止淘汰资料,当存储器达到阈值的时候,新写入操作报错
-
volatile-lfu:从已设定过期时间的资料集(server.db[i].expires)中挑选最不经常使用的资料淘汰(LFU(Least Frequently Used)算法,也就是最频繁被访问的资料将来最有可能被访问到)
-
allkeys-lfu:当存储器不足以容纳新写入资料时,在键空间中,移除最不经常使用的key,
Redis 突然挂了怎么解决?
答案:1、从系统可用性角度思考,Redis Cluster引入主备机制,当主节点挂了后,自动切换到备用节点,继续提供服务,2、Client端引入本地快取,通过开关切换,避免Redis突然挂掉,高并发流量把数据库打挂,
Redis 持久化有哪些方式?
答案:
1、快照RDB,将某个时间点上的数据库状态保存到RDB档案中,RDB档案是一个压缩的二进制档案,保存在磁盘上,当Redis崩溃时,可用于恢复资料,通过SAVE或BGSAVE来生成RDB档案,
-
SAVE:会阻塞redis行程,直到RDB档案创建完毕,在行程阻塞期间,redis不能处理任何命令请求,
-
BGSAVE:会fork出一个子行程,然后由子行程去负责生成RDB档案,父行程还可以继续处理命令请求,不会阻塞行程,
2、只追加档案AOF,以日志的形式记录每个写操作(非读操作),当不同节点同步资料时,读取日志档案的内容将写指令从前到后执行一次,即可完成资料恢复,
Redis 常用场景
答案:
-
1、快取,有句话说的好,「性能不够,快取来凑」
-
2、分布式锁,利用Redis 的 setnx
-
3、分布式session
-
4、计数器,通过incr命令
-
5、排行榜,Redis 的 有序集合
-
6、其他
Redis 快取要注意的七大经典问题?
答案:列举了亿级系统,高访问量情况下Redis快取可能会遇到哪些问题?以及对应的解决方案,
-
1、快取集中失效
-
2、快取穿透
-
3、快取雪崩
-
4、快取热点
-
5、快取大Key
-
6、快取资料的一致性
-
7、资料并发竞争预热
每个问题的详细解决方案,请查看 亿级系统的Redis快取如何设计???
Redis 集群方案有哪几种?
答案:
-
主从复制模式
-
Sentinel(哨兵)模式
-
Redis Cluster模式
Redis 主从资料同步(主从复制)的程序?
答案:
-
1、slave启动后,向master发送sync命令
-
2、master收到sync之后,执行bgsave保存快照,生成RDB全量档案
-
3、master把slave的写命令记录到快取
-
4、bgsave执行完毕之后,发送RDB档案到slave,slave执行
-
5、master发送缓冲区的写命令给slave,slave接收命令并执行,完成复制初始化,
-
6、此后,master每次执行一个写命令都会同步发送给slave,保持master与slave之间资料的一致性
主从复制的优缺点?
答案:
1、优点:
-
master能自动将资料同步到slave,可以进行读写分离,分担master的读压力
-
master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
-
不具备自动容错与恢复功能,master 节点宕机后,需要手动指定新的 master
-
master宕机,如果宕机前资料没有同步完,则切换IP后会存在资料不一致的问题
-
难以支持在线扩容,Redis的容量受限于单机配置
Sentinel(哨兵)模式的优缺点?
答案:哨兵模式基于主从复制模式,增加了哨兵来监控与自动处理故障,
1、优点:
-
哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
-
master 挂掉可以自动进行切换,系统可用性更高
2、缺点:
-
Redis的容量受限于单机配置
-
需要额外的资源来启动sentinel行程
Redis Cluster 模式的优缺点?
答案:实作了Redis的分布式存盘,即每台节点存盘不同的内容,来解决在线扩容的问题,
1、优点:
-
无中心架构,资料按照slot分布在多个节点
-
集群中的每个节点都是平等的,每个节点都保存各自的资料和整个集群的状态,每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的资料,
-
可线性扩展到1000多个节点,节点可动态添加或洗掉
-
能够实作自动故障转移,节点之间通过
gossip协议交换状态信息,用投票机制完成slave到master的角色转换
缺点:
-
资料通过异步复制,不保证资料的强一致性
-
slave充当 “冷备”,不对外提供读、写服务,只作为故障转移使用,
-
批量操作限制,目前只支持具有相同slot值的key执行批量操作,对mset、mget、sunion等操作支持不友好
-
key事务操作支持有限,只支持多key在同一节点的事务操作,多key分布在不同节点时无法使用事务功能
-
不支持多数据库空间,一台redis可以支持16个db,集群模式下只能使用一个,即
db 0,Redis Cluster模式不建议使用pipeline和multi-keys操作,减少max redirect产生的场景,
Redis 如何做扩容?
答案:为了避免资料迁移失效,通常使用一致性哈希实作动态扩容缩容,有效减少需要迁移的Key数量,
但是Cluster 模式,采用固定Slot槽位方式(16384个),对每个key计算CRC16值,然后对16384取模,然后根据slot值找到目标机器,扩容时,我们只需要迁移一部分的slot到新节点即可,
Redis 的集群原理?
答案:一个redis集群由多个节点node组成,而多个node之间通过cluster meet命令来进行连接,组成一个集群,
资料存盘通过分片的形式,整个集群分成了16384个slot,每个节点负责一部分槽位,整个槽位的信息会同步到所有节点中,
key与slot的映射关系:
-
健值对 key,进行
CRC16计算,计算出一个 16 bit 的值 -
将 16 bit 的值对 16384 取模,得到 0 ~ 16383 的数表示 key 对应的哈希槽
Redis 如何做到高可用?
答案:哨兵机制,具有自动故障转移、集群监控、讯息通知等功能,
哨兵可以同时监视所有的主、从服务器,当某个master下线时,自动提升对应的slave为master,然后由新master对外提供服务,
什么是 Redis 事务?
答案:Redis事务是一组命令的集合,将多个命令打包,然后把这些命令按顺序添加到队列中,并且按顺序执行这些命令,
Redis事务中没有像Mysql关系型数据库事务隔离级别的概念,不能保证原子性操作,也没有像Mysql那样执行事务失败会进行回滚操作
Redis 事务执行流程?
答案:通过MULTI、EXEC、WATCH等命令来实作事务机制,事务执行程序将一系列多个命令按照顺序一次性执行,在执行期间,事务不会被中断,也不会去执行客户端的其他请求,直到所有命令执行完毕,
具体程序:
-
服务端收到客户端请求,事务以
MULTI开始 -
如果正处于事务状态时,则会把后续命令放入队列同时回传给客户端
QUEUED,反之则直接执行这 个命令 -
当收到客户端的
EXEC命令时,才会将队列里的命令取出、顺序执行,执行完将当前状态从事务状态改为非事务状态 -
如果收到
DISCARD命令,放弃执行队列中的命令,可以理解为Mysql的回滚操作,并且将当前的状态从事务状态改为非事务状态
WATCH 监视某个key,该命令只能在MULTI命令之前执行,如果监视的key被其他客户端修改,EXEC将会放弃执行队列中的所有命令,UNWATCH 取消监视之前通过WATCH 命令监视的key,通过执行EXEC 、DISCARD 两个命令之前监视的key也会被取消监视,
Redis 与 Guava 、Caffeine 有什么区别?
答案:快取分为本地快取和分布式快取,
1、Caffeine、Guava,属于本地快取,特点:
-
直接访问记忆体,速度快,受存储器限制,无法进行大资料存盘,
-
无网络通讯开销,性能更高,
-
只支持本地应用行程访问,同步更新所有节点的本地快取资料成本较高,
-
应用行程重启,资料会丢失,
所以,本地快取适合存盘一些不易改变或者低频改变的高热点资料,
2、Redis属于分布式快取,特点:
-
集群模式,支持大资料量存盘
-
资料集中存盘,保证资料的一致性
-
资料跨网络传输,性能低于本地快取,但同一个机房,两台服务器之间请求跑一个来回也就需要500微秒,比起其优势,这点损耗完全可以忽略,这也是分布式快取受欢迎的原因,
-
支持副本机制,有效的保证了高可用性,
如何实作一个分布式锁?
答案:
-
1、数据库表,性能比较差
-
2、使用Lua脚本 (包含 SETNX + EXPIRE 两条指令)
-
3、SET的扩展命令(SET key value [EX][PX] [NX|XX])
-
4、Redlock 框架
-
5、Zookeeper Curator框架提供了现成的分布式锁
我是Tom哥~
校招进阿里,期间还拿了 百度、华为、中兴、腾讯 等6家大厂offer,P7 技术专家,出过专利,CSDN博客专家,多次淘宝双11活动方案,专注于微服务、高并发、分布式架构、高可用等领域,喜欢挖掘开源框架亮点设计,
1、Java高频考点
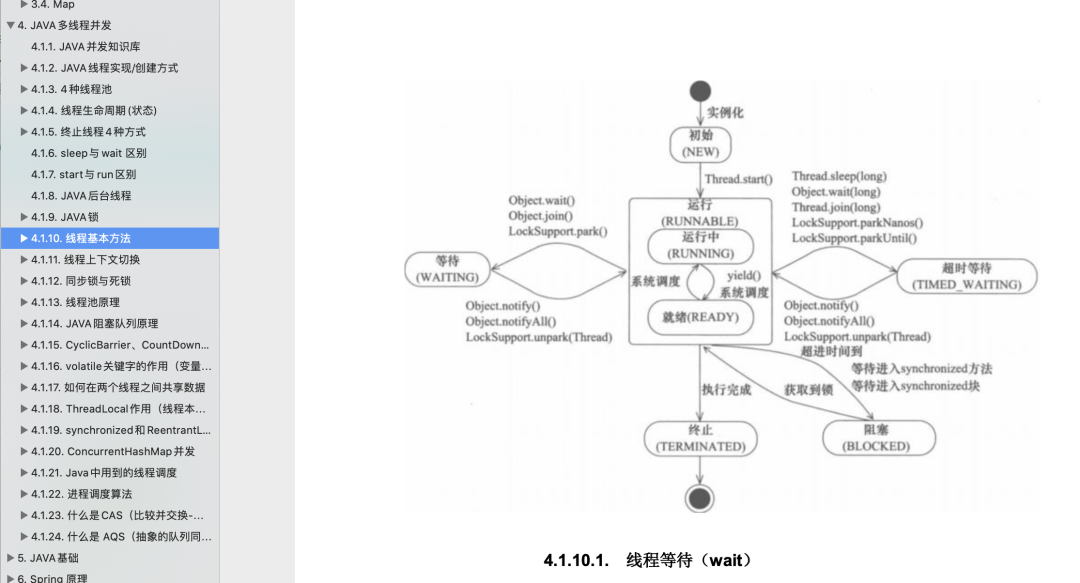
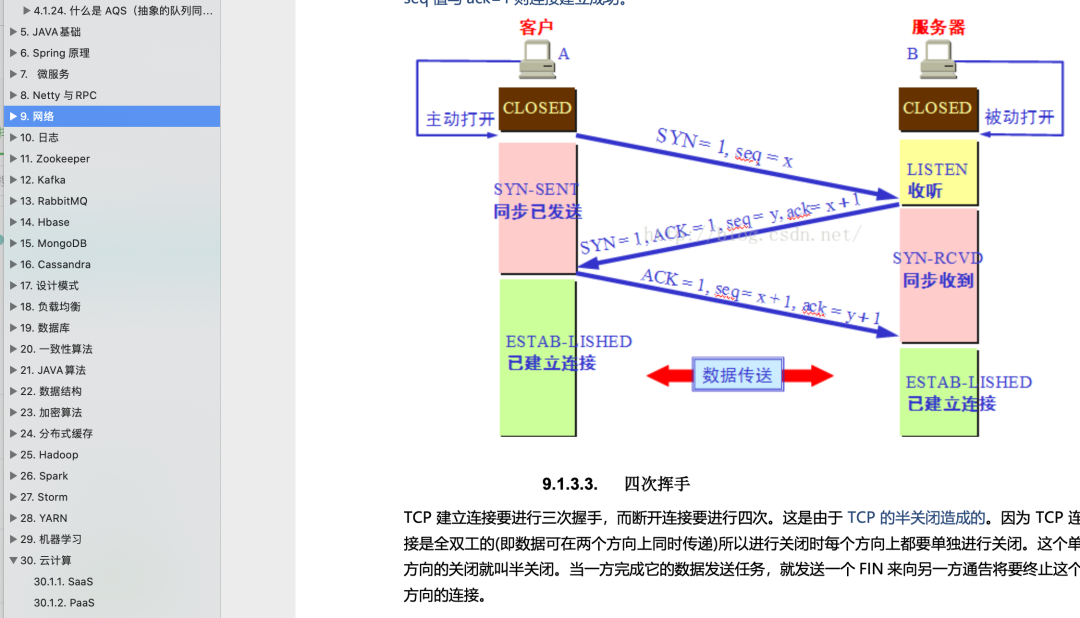
2、计算机网络
3、LeetCode算法

作为一线大厂的面试官,Tom哥收集很多大厂的高频面试题,扫描下方的二维码,关注公众号【微观技术】,后台回复 “666”、“算法”,免费领取相关学习资料,
已经帮助身边很多小伙伴进入字节、阿里等一线大厂,也欢迎小伙伴找Tom哥唠嗑聊天, 技术交流,围观朋友圈,人生打怪不再寂寞








0 评论