1.概述
在本教程中,我们将探索使用Apache Kafka进行事件驱动架构的数据建模领域。
2.配置Kafka集群
一个Kafka集群由在Zookeeper集群中注册的多个Kafka代理组成。为了简单起见,我们将使用Confluent发布的现成的Docker映像和docker-compose配置。
首先,让我们下载3节点Kafka集群docker-compose.yml :
$ BASE_URL="https://raw.githubusercontent.com/confluentinc/cp-docker-images/5.3.3-post/examples/kafka-cluster"
$ curl -Os "$BASE_URL"/docker-compose.yml接下来,让我们启动Zookeeper和Kafka代理节点:
$ docker-compose up -d最后,我们可以验证所有Kafka经纪人都在工作:
$ docker-compose logs kafka-1 kafka-2 kafka-3 | grep started
kafka-1_1 | [2020-12-27 10:15:03,783] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
kafka-2_1 | [2020-12-27 10:15:04,134] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
kafka-3_1 | [2020-12-27 10:15:03,853] INFO [KafkaServer id=3] started (kafka.server.KafkaServer)3.活动基础
在承担事件驱动系统的数据建模任务之前,我们需要了解一些概念,例如事件,事件流,生产者-消费者和主题。
3.1。事件
卡夫卡世界中的事件是域世界中发生的事情的信息日志。它通过将信息记录为键值对消息以及其他一些属性(例如时间戳,元信息和标头)来完成此操作。
假设我们正在建模一个国际象棋游戏;那么一个事件可能就是一个举动:
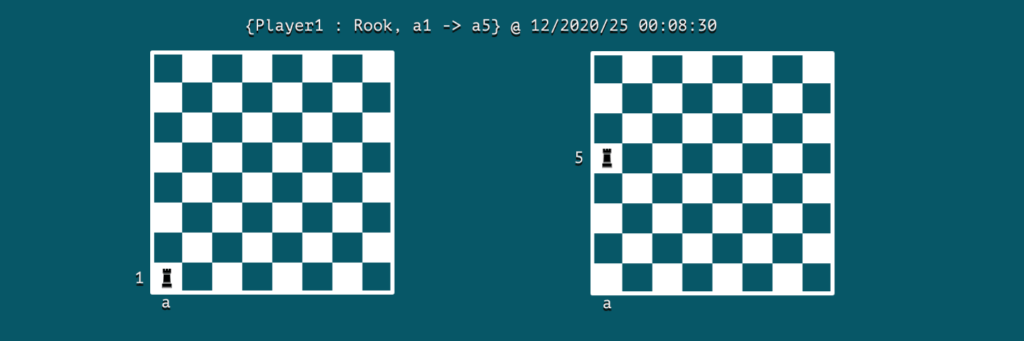
我们可以注意到事件包含了参与者的关键信息,动作和事件发生的时间。在这种情况下, Player1是演员,并且动作是在12/2020/25 00:08:30将菜鸟从单元格a1移动到a5 。
3.2 消息流
Apache Kafka是一种流处理系统,可将事件捕获为消息流。在我们的国际象棋游戏中,我们可以将事件流视为玩家下棋的记录。
在每个事件发生时,板的快照将代表其状态。通常,使用传统的表模式存储对象的最新静态状态。
另一方面,事件流可以帮助我们以事件的形式捕获两个连续状态之间的动态变化。如果我们播放一系列这些不可变的事件,则可以从一个状态转换到另一个状态。这就是事件流和传统表之间的关系,通常称为流表对偶。
让我们在棋盘上通过两个连续事件可视化事件流:
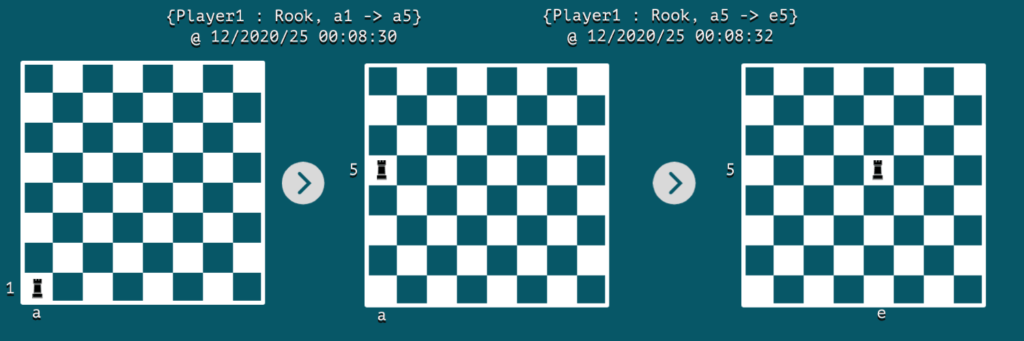
4.主题
在本节中,我们将学习如何对通过Apache Kafka路由的消息进行分类。
4.1。分类
在诸如Apache Kafka之类的消息传递系统中,任何产生事件的事件通常称为生产者。那些阅读和消费这些消息的人称为消费者。
在现实情况中,每个生产者可以生成不同类型的事件,因此,如果我们希望他们过滤与他们相关的消息并忽略其余消息,那么这将浪费大量的精力。
为了解决这个基本问题, Apache Kafka使用的主题本质上是属于在一起的消息组。结果,消费者可以在消费事件消息的同时提高生产力。
在我们的国际象棋棋盘示例中,可以使用一个主题将所有chess-moves分组到chess-moves主题下:
$ docker run \
--net=host --rm confluentinc/cp-kafka:5.0.0 \
kafka-topics --create --topic chess-moves \
--if-not-exists
--zookeeper localhost:32181
Created topic "chess-moves".4.2。生产者-消费者
现在,让我们看看生产者和消费者如何使用Kafka的主题进行消息处理。我们将使用Kafka发行版随附的kafka-console-producer和kafka-console-consumer实用程序进行演示。
让我们启动一个名为kafka-producer的容器,其中将调用producer实用程序:
$ docker run \
--net=host \
--name=kafka-producer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
同时,我们可以启动一个名为kafka-consumer的容器,在其中调用消费者工具:
$ docker run \
--net=host \
--name=kafka-consumer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true --property key.separator=:
现在,让我们记录一下制作人中的一些游戏动作:
>{Player1 : Rook, a1->a5}当使用者处于活动状态时,它将使用密钥Player1接收以下消息:
{Player1 : Rook, a1->a5}5.分区
接下来,让我们看看如何使用分区创建消息的进一步分类并提高整个系统的性能。
5.1。并发
我们可以将一个主题划分为多个分区,并调用多个使用者以使用来自不同分区的消息。通过启用这种并发行为,可以提高系统的整体性能。
默认情况下,除非在创建主题时明确指定,Kafka会创建主题的单个分区。但是,对于先前存在的主题,我们可以增加分区的数量。让我们将chess-moves主题的分区号设置为3 :
$ docker run \
--net=host \
--rm confluentinc/cp-kafka:5.0.0 \
bash -c "kafka-topics --alter --zookeeper localhost:32181 --topic chess-moves --partitions 3"
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!5.2。分区键
在一个主题内,Kafka使用分区键跨多个分区处理消息。一方面,生产者隐式使用它来将消息路由到分区之一。另一方面,每个使用者都可以从特定分区读取消息。
默认情况下,生产者将生成键的哈希值,后跟具有分区数的模数。然后,它将消息发送到由计算出的标识符标识的分区。
让我们使用kafka-console-producer实用工具创建新的事件消息,但是这次我们将记录两个玩家的动作:
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
>{Player1: Rook, a1 -> a5}
>{Player2: Bishop, g3 -> h4}
>{Player1: Rook, a5 -> e5}
>{Player2: Bishop, h4 -> g3}现在,我们可以有两个使用者,一个从分区1读取,另一个从分区2读取:
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true \
--property key.separator=: \
--partition 1
{Player2: Bishop, g3 -> h4}
{Player2: Bishop, h4 -> g3}我们可以看到Player2的所有移动都被记录在partition-1中。同样,我们可以检查Player1的移动是否已记录到分区0中。
6.水平扩展
我们如何概念化主题和分区对于水平扩展至关重要。一方面,主题更多是数据的预定义分类。另一方面,分区是动态发生的数据动态分类。
此外,在一个主题中可以配置多少个分区方面存在实际限制。这是因为每个分区都映射到代理节点文件系统中的目录。当我们增加分区数量时,我们也增加了操作系统上打开文件句柄的数量。
根据经验, Confluent的**专家 **建议将每个代理的分区数限制为100 x b x r ,其中b是Kafka群集中的代理数, r是复制因子。
7.结论
在本文中,我们使用Docker环境介绍了使用Apache Kafka进行消息处理的系统的数据建模基础。在对事件,主题和分区有基本的了解之后,我们现在就可以概念化事件流并进一步使用此体系结构范例。








0 评论