1.概述
在本教程中,我们将研究使用JobRunr在Java中进行分布式后台作业调度和处理,并将其与Spring集成。
2.关于JobRunr
JobRunr是一个我们可以嵌入到我们的应用程序中的库,它允许我们使用Java 8 lambda调度后台作业。我们可以使用Spring服务的任何现有方法来创建作业,而无需实现接口。作业可以是短期的,也可以是长期运行的,它将自动卸载到后台线程,这样就不会阻止当前的Web请求。
为此,JobRunr分析了Java 8 lambda。它将其序列化为JSON,并将其存储到关系数据库或NoSQL数据存储中。
3. JobRunr功能
如果我们看到我们正在生成过多的后台作业,而我们的服务器无法应付负载,则可以通过添加应用程序的额外实例来轻松地水平扩展。 JobRunr将自动分担负载,并在我们应用程序的不同实例上分配所有作业。
它还包含自动重试功能,并为失败的作业提供了指数补偿策略。还有一个内置的仪表板,使我们可以监视所有作业。 JobRunr是自我维护的–成功的作业将在可配置的时间后自动删除,因此无需执行手动存储清理。
4.设定
为了简单起见,我们将使用内存中的数据存储来存储所有与作业相关的信息。
4.1 Maven配置
让我们直接跳到Java代码。但是在此之前,我们需要在pom.xml文件中声明以下Maven依赖项:
<dependency>
<groupId>org.jobrunr</groupId>
<artifactId>jobrunr-spring-boot-starter</artifactId>
<version>1.1.0</version>
</dependency>4.2 Spring整合
在我们直接转到如何创建后台作业之前,我们需要初始化JobRunr。由于我们正在使用jobrunr-spring-boot-starter依赖项,因此这很容易。我们只需要向application.properties添加一些属性:
org.jobrunr.background-job-server.enabled=true
org.jobrunr.dashboard.enabled=true第一个属性告诉JobRunr我们要启动一个负责处理作业BackgroundJobServer第二个属性告诉JobRunr启动嵌入式仪表板。
默认情况下,如果有关系数据库来存储所有与作业相关的信息jobrunr-spring-boot-starter会尝试使用您现有的DataSource
但是,由于我们将使用内存中的数据存储,因此我们需要提供一个StorageProvider bean:
@Bean
public StorageProvider storageProvider(JobMapper jobMapper) {
InMemoryStorageProvider storageProvider = new InMemoryStorageProvider();
storageProvider.setJobMapper(jobMapper);
return storageProvider;
}5.用法
现在,让我们了解如何使用JobRunr在Spring中创建和安排后台作业。
5.1 注入依赖
当我们要创建作业时,我们需要注入JobScheduler和我们现有的Spring服务,其中包含我们要为其创建作业的方法,在本例中为SampleJobService :
@Inject
private JobScheduler jobScheduler;
@Inject
private SampleJobService sampleJobService;JobScheduler类允许我们排队或安排新的后台作业。
SampleJobService可以是我们现有的任何Spring服务,其中包含一种方法,该方法可能需要很长时间才能在Web请求中处理。它也可以是在其他我们要添加弹性的外部服务上调用的方法,因为如果发生异常,JobRunr将重试该方法。
5.2 创建一劳永逸的工作
现在我们有了依赖关系,我们可以使用enqueue方法enqueue
jobScheduler.enqueue(() -> sampleJobService.executeSampleJob());作业可以具有参数,就像其他任何lambda一样:
jobScheduler.enqueue(() -> sampleJobService.executeSampleJob("some string"));该行确保将lambda(包括类型,方法和参数)作为JSON序列化为持久性存储(Oracle,Postgres,MySql和MariaDB之类的RDBMS或NoSQL数据库)。
BackgroundJobServer运行的专用线程工作池将以先进先出的方式尽快执行这些排队的后台作业。 JobRunr通过乐观锁定保证单个工人执行您的工作。
5.3 计划将来的作业
我们还可以使用schedule方法来计划将来的作业:
jobScheduler.schedule(() -> sampleJobService.executeSampleJob(), LocalDateTime.now().plusHours(5));5.4 定期周期性作业
如果我们想拥有周期性工作,则需要使用scheduleRecurrently方法:
jobScheduler.scheduleRecurrently(() -> sampleJobService.executeSampleJob(), Cron.hourly());5.5 使用@Job批注进行批注
为了控制作业的各个方面,我们可以使用@Job批注来批注我们的服务方法。这样可以在仪表板中设置显示名称,并配置万一作业失败的重试次数。
@Job(name = "The sample job with variable %0", retries = 2)
public void executeSampleJob(String variable) {
...
}String.format()语法以显示名称传递给作业的变量。
如果我们有非常特定的用例,仅希望在特定的例外情况下重试特定的作业,则可以编写自己的ElectStateFilter ,在其中我们可以访问Job并完全控制执行方式。
6.仪表板
JobRunr带有内置的仪表板,可让我们监视作业。我们可以在http:// localhost:8000上找到它,并检查所有作业,包括所有重复发生的作业,以及在处理所有排队的作业之前需要多长时间的估计:
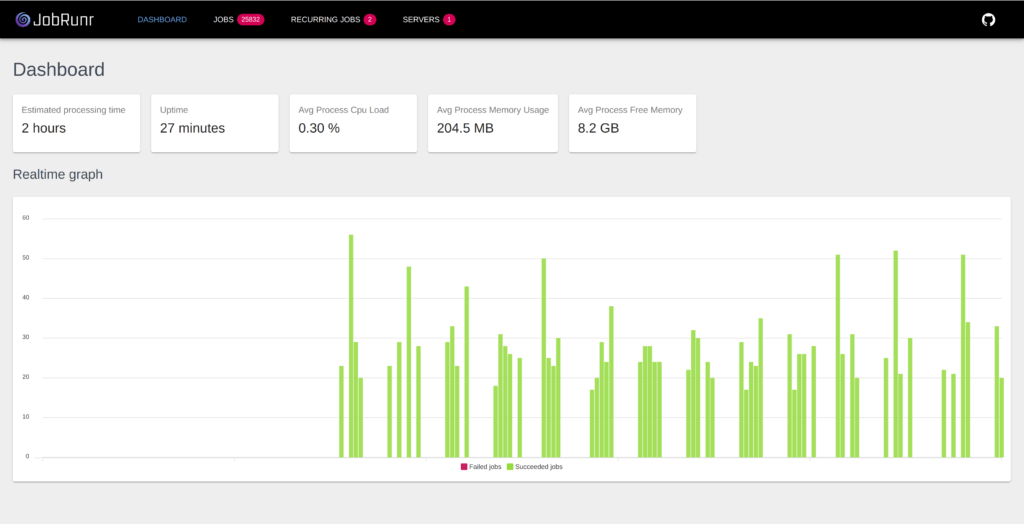
可能发生不好的事情,例如SSL证书过期或磁盘已满。默认情况下,JobRunr将使用指数退避策略重新计划后台作业。如果后台作业继续失败十次,则只有这样才能进入Failed状态。解决了根本原因后,您可以决定重新排队失败的作业。
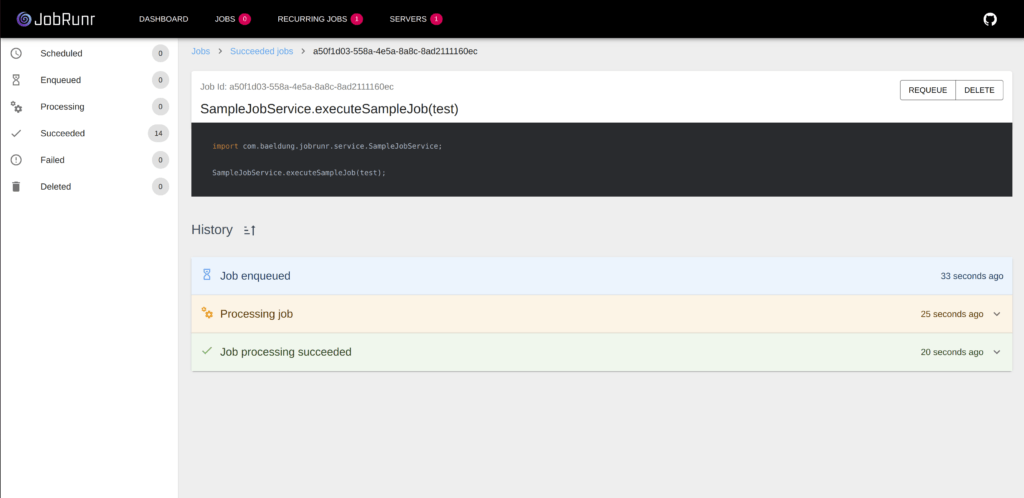
所有这些信息在仪表板中都是可见的,包括每次重试以及确切的错误消息和作业失败原因的完整堆栈跟踪:
7.结论
在本文中,我们使用Jobrunr和jobrunr-spring-boot-starter构建了第一个基本调度程序。本教程的主要收获是,我们能够仅用一行代码创建作业,而无需任何基于XML的配置或实现接口的需要。








0 评论